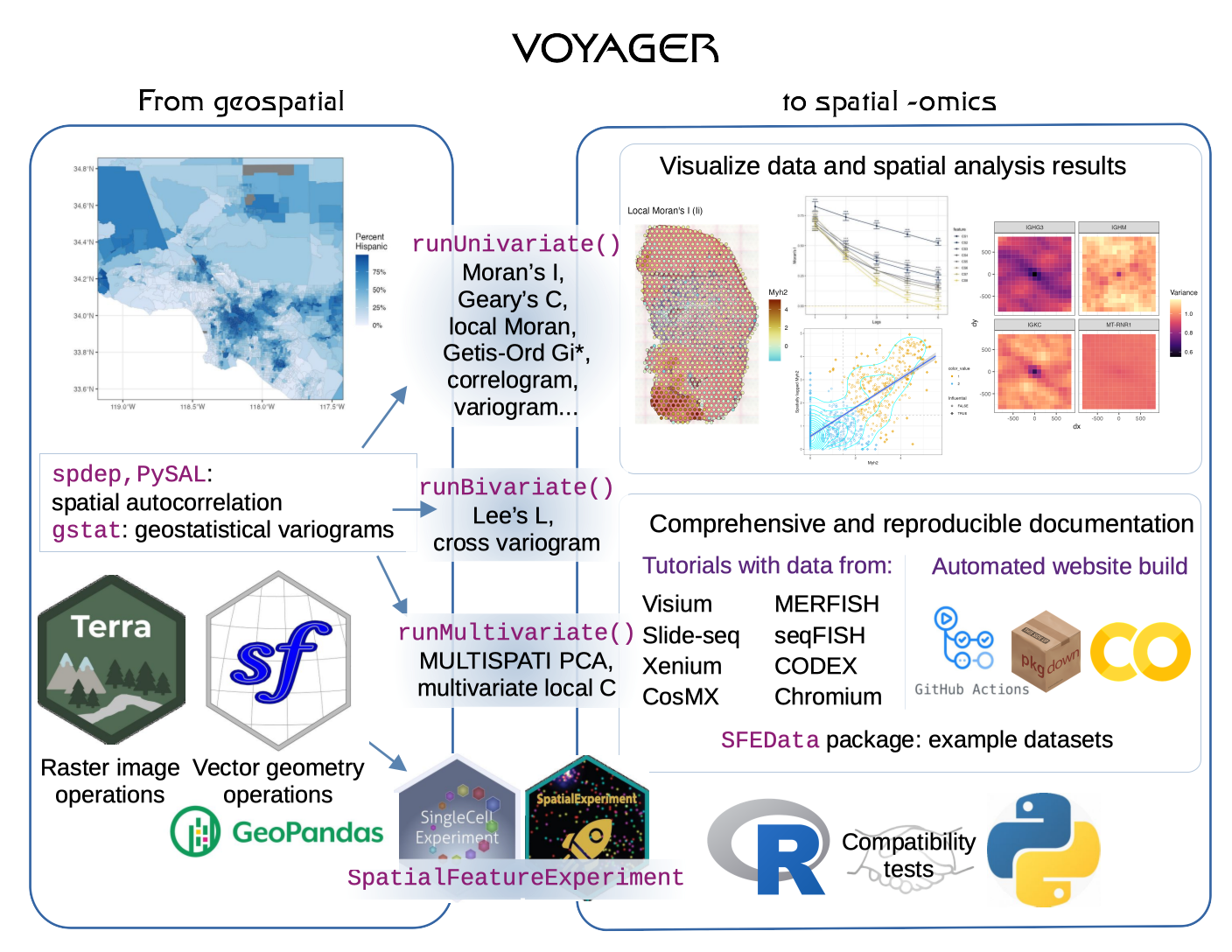
Exploratory spatial data analysis with Voyager
Lambda Moses
dlu2@caltech.eduLior Pachter
lpachter@caltech.edu2023-08-02
Source:vignettes/workshop.Rmd
workshop.RmdIntroduction
Introduction slides are available here. The rendered version of this workshop is available here. The following R packages are used in this workshop, which are all on CRAN or Bioconductor. Bioconductor 3.17 is used in the workshop presented at Bioc2023.
library(SpatialFeatureExperiment)
library(SingleCellExperiment)
library(Voyager)
library(SFEData)
library(scran)
library(scater)
library(ggplot2)
library(rjson)
library(Matrix)
library(sf)
library(scales)
library(patchwork)
library(BiocParallel)
library(tibble)
library(tidyr)
library(scico)
library(pheatmap)
library(BiocNeighbors)
library(BiocSingular)
library(bluster)
theme_set(theme_bw())
SpatialFeatureExperiment
SpatialFeatureExperiment (SFE) is a new S4 class built on top of SpatialExperiment
(SPE). SFE incorporates geometries and geometric operations with the sf
package. Examples of supported geometries are Visium spots represented
with polygons corresponding to their size, cell or nuclei segmentation
polygons, tissue boundary polygons, pathologist annotation of
histological regions, and transcript spots of genes. Using
sf, SpatialFeatureExperiment leverages the
GEOS C++ library underlying sf for geometry operations,
including algorithms for for determining whether geometries intersect,
finding intersection geometries, buffering geometries with margins, etc.
A schematic of the SFE object is shown below:
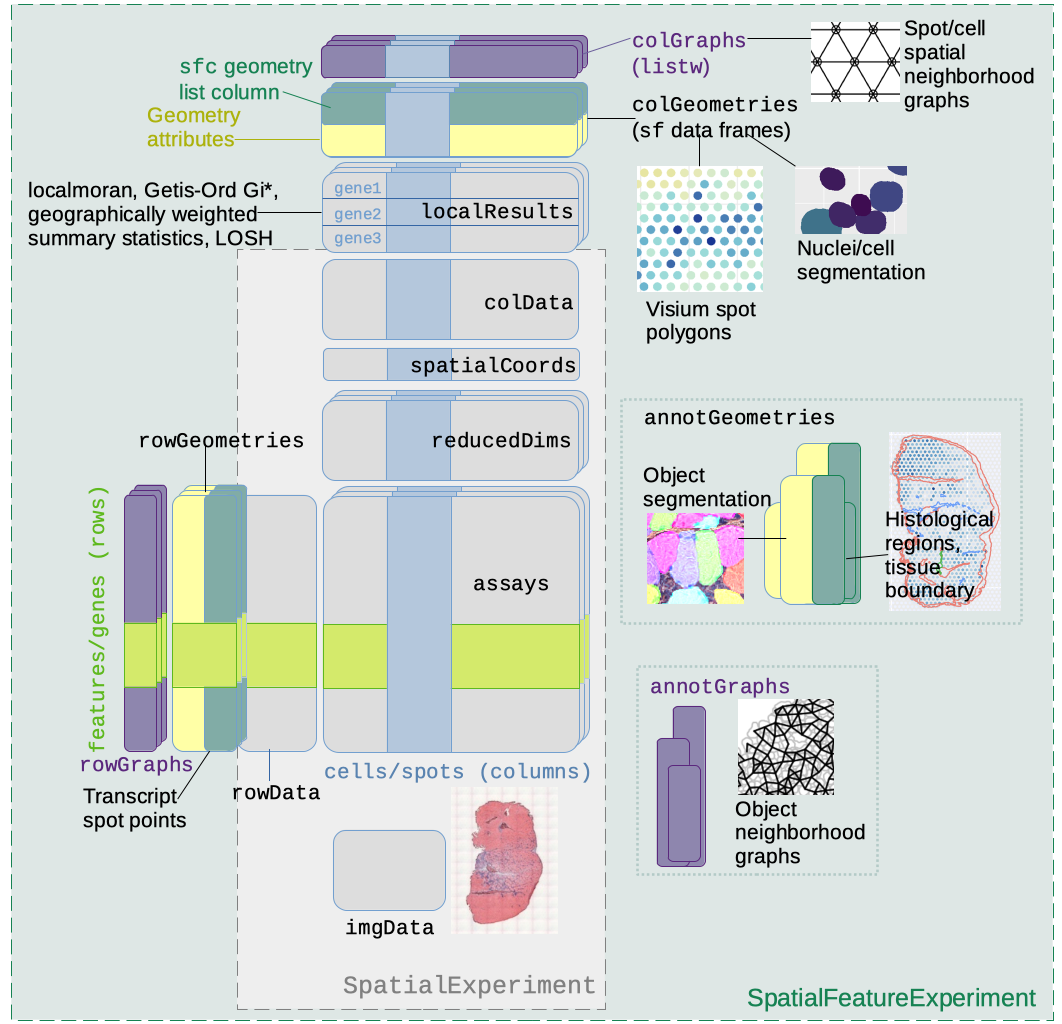
Below is a list of SFE features that extend the SPE object:
-
colGeometriesaresfdata frames associated with the entities that correspond to columns of the gene count matrix, such as Visium spots or cells. The geometries in thesfdata frames can be Visium spot centroids, Visium spot polygons, or for datasets with single cell resolution, cell or nuclei segmentations. MultiplecolGeometriescan be stored in the same SFE object, such as one for cell segmentation and another for nuclei segmentation. There can be non-spatial, attribute columns in acolGeometryrather thancolData, because thesfclass allows users to specify how attributes relate to geometries, such as “constant”, “aggregate”, and “identity”. See theagrargument of thest_sfdocumentation. -
colGraphsare spatial neighborhood graphs of cells or spots. The graphs have classlistw(spdeppackage), and thecolPairsofSingleCellExperimentwas not used so no conversion is necessary to use the numerous spatial dependency functions fromspdep, such as those for Moran’s I, Geary’s C, Getis-Ord Gi*, LOSH, etc. Conversion is also not needed for other classical spatial statistics packages such asspatialregandadespatial. -
rowGeometriesare similar tocolGeometries, but support entities that correspond to rows of the gene count matrix, such as genes. A potential use case is to store transcript spots for each gene in smFISH or in situ sequencing based datasets. -
rowGraphsare similar tocolGraphs. A potential use case may be spatial colocalization of transcripts of different genes. -
annotGeometriesaresfdata frames associated with the dataset but not directly with the gene count matrix, such as tissue boundaries, histological regions, cell or nuclei segmentation in Visium datasets, and etc. These geometries are stored in this object to facilitate plotting and usingsffor operations such as to find the number of nuclei in each Visium spot and which histological regions each Visium spot intersects. UnlikecolGeometriesandrowGeometries, the number of rows in thesfdata frames inannotGeometriesis not constrained by the dimension of the gene count matrix and can be arbitrary. -
annotGraphsare similar tocolGraphsandrowGraphs, but are for entities not directly associated with the gene count matrix, such as spatial neighborhood graphs for nuclei in Visium datasets, or other objects like myofibers. These graphs are relevant tospdepanalyses of attributes of these geometries such as spatial autocorrelation in morphological metrics of myofibers and nuclei. With geometry operations withsf, these attributes and results of analyses of these attributes (e.g. spatial regions defined by the attributes) may be related back to gene expression. -
localResultsare similar toreducedDimsinSingleCellExperiment, but stores results from univariate and bivariate local spatial analysis results, such as fromlocalmoran, Getis-Ord Gi*, and local spatial heteroscedasticity (LOSH). Unlike inreducedDims, for each type of results (type is the type of analysis such as Getis-Ord Gi*), each feature (e.g. gene) or pair of features for which the analysis is performed has its own results. The local spatial analyses can also be performed for attributes ofcolGeometriesandannotGeometriesin addition to gene expression andcolData. Results of multivariate spatial analysis such as MULTISPATI PCA can be stored inreducedDims.
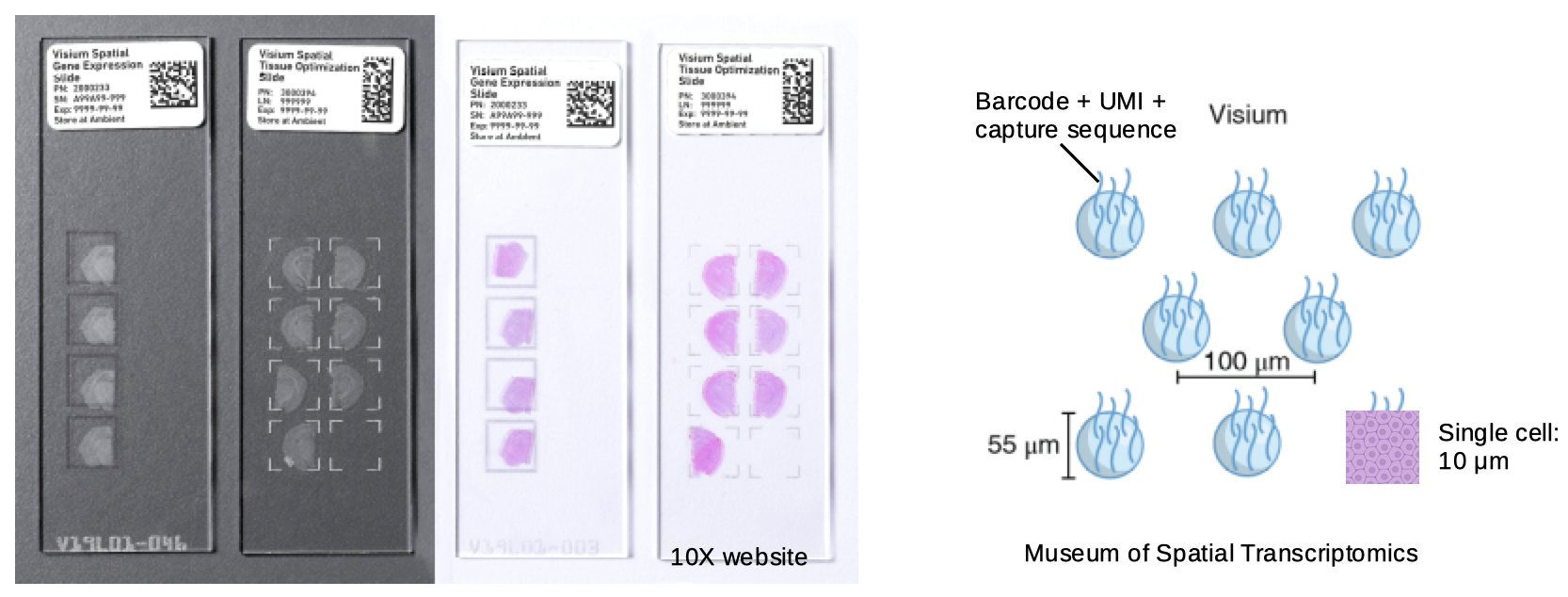
10X Visium
As Visium from 10X Genomics is currently the most popular spatial transcriptomics technology, this workshop uses a Visium dataset.
In Visium, capture sequences with spot barcode, unique molecule identifier (UMI), and polyT to capture poly-adenylated mRNAs are printed in a hexagonal array on a glass slide. Each spot barcode has a known location, and the spots are 55 \(\mu m\) in diameter and 100 \(\mu m\) apart center to center. As the spots are much larger than most types of cells, Visium does not have single cell resolution. Tissue is mounted on each of the 4 capture areas on the slide, and each capture area has 4992 spots. The spots capture the transcripts from the tissue, which are then reverse transcribed, amplified, and sequenced.
Space Ranger is the official software to align the sequencing reads to the genome and quantify the UMIs in each spot for each gene. Spatial Ranger also takes in a histology image of the capture area, with which it determines which spots are in tissue. The user can also manually determine which spots are in tissue in the Loupe Browser.
Part 1: The SFE class
Create an SFE object
10x Genomics Space Ranger output from a Visium experiment can be read
in a similar manner as in SpatialExperiment; the
SpatialFeatureExperiment SFE object has the
spotPoly column geometry for the spot polygons. If the
filtered matrix (i.e. only spots in the tissue) is read in, then a
column graph called visium will also be present for the
spatial neighborhood graph of the Visium spots on the tissue. The graph
is not computed if all spots are read in regardless of whether they are
on tissue.
dir <- system.file("extdata", package = "SpatialFeatureExperiment")
sample_ids <- c("sample01", "sample02")
(samples <- file.path(dir, sample_ids))
#> [1] "/usr/local/lib/R/site-library/SpatialFeatureExperiment/extdata/sample01"
#> [2] "/usr/local/lib/R/site-library/SpatialFeatureExperiment/extdata/sample02"The results for each tissue capture should be in the
outs directory under the sample directory. Inside the
outs directory, these directories may be present:
raw_reature_bc_matrix has the unfiltered gene count matrix,
filtered_feature_bc_matrix has the gene count matrix for
spots in tissue, and spatial has the spatial information.
The matrix directories contain the matrices in MTX format as sparse
matrices. Space Ranger also outputs the matrices as h5 files, which are
read into R in a similar way as MTX.
list.files(file.path(samples[1], "outs"))
#> [1] "filtered_feature_bc_matrix" "spatial"Inside the matrix directory:
list.files(file.path(samples[1], "outs", "filtered_feature_bc_matrix"))
#> [1] "barcodes.tsv" "features.tsv" "matrix.mtx"Inside the spatial directory:
list.files(file.path(samples[1], "outs", "spatial"))
#> [1] "aligned_fiducials.jpg" "barcode_fluorescence_intensity.csv"
#> [3] "detected_tissue_image.jpg" "scalefactors_json.json"
#> [5] "spatial_enrichment.csv" "tissue_hires_image.png"
#> [7] "tissue_lowres_image.png" "tissue_positions.csv"tissue_lowres_image.png is a low resolution image of the
tissue. Not all Visium datasets have all the files here. The
barcode_fluorescence_intensity.csv file is only present in
datasets with fluorescent imaging rather than bright field H&E.
(sfe3 <- read10xVisiumSFE(samples, sample_id = sample_ids, type = "sparse",
data = "filtered"))
#> class: SpatialFeatureExperiment
#> dim: 5 25
#> metadata(0):
#> assays(1): counts
#> rownames(5): ENSG00000014257 ENSG00000142515 ENSG00000263639
#> ENSG00000163810 ENSG00000149591
#> rowData names(14): symbol Feature.Type ...
#> Median.Normalized.Average.Counts_sample02
#> Barcodes.Detected.per.Feature_sample02
#> colnames(25): GTGGCGTGCACCAGAG-1 GGTCCCATAACATAGA-1 ...
#> TGCAATTTGGGCACGG-1 ATGCCAATCGCTCTGC-1
#> colData names(10): in_tissue array_row ... channel3_mean channel3_stdev
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
#> spatialCoords names(2) : pxl_col_in_fullres pxl_row_in_fullres
#> imgData names(4): sample_id image_id data scaleFactor
#>
#> unit: full_res_image_pixel
#> Geometries:
#> colGeometries: spotPoly (POLYGON)
#>
#> Graphs:
#> sample01: col: visium
#> sample02: col: visiumSpace Ranger output includes the gene count matrix, spot coordinates, and spot diameter. The Space Ranger output does NOT include nuclei segmentation or pathologist annotation of histological regions. Extra image processing, such as with ImageJ and QuPath, are required for those geometries.
See this vignette on creating SFE objects from scratch and for other spatial trancriptomics technologies.
Operations of SFE objects
User interfaces to get or set the geometries and spatial graphs
emulate those of reducedDims and row/colPairs
in SingleCellExperiment. Column and row geometries also
emulate reducedDims in internal implementation, while
annotation geometries and spatial graphs differ. Operations on SFE
objects are demonstrated on a small toy dataset (you may need to answer
a prompt in the R console when downloading the dataset):
(sfe <- McKellarMuscleData(dataset = "small"))
#> see ?SFEData and browseVignettes('SFEData') for documentation
#> loading from cache
#> class: SpatialFeatureExperiment
#> dim: 15123 77
#> metadata(0):
#> assays(1): counts
#> rownames(15123): ENSMUSG00000025902 ENSMUSG00000096126 ...
#> ENSMUSG00000064368 ENSMUSG00000064370
#> rowData names(6): Ensembl symbol ... vars cv2
#> colnames(77): AAATTACCTATCGATG AACATATCAACTGGTG ... TTCTTTGGTCGCGACG
#> TTGATGTGTAGTCCCG
#> colData names(12): barcode col ... prop_mito in_tissue
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
#> spatialCoords names(2) : imageX imageY
#> imgData names(1): sample_id
#>
#> unit: full_res_image_pixels
#> Geometries:
#> colGeometries: spotPoly (POLYGON)
#> annotGeometries: tissueBoundary (POLYGON), myofiber_full (GEOMETRY), myofiber_simplified (GEOMETRY), nuclei (POLYGON), nuclei_centroid (POINT)
#>
#> Graphs:
#> Vis5A:Column geometries
Column geometries or colGeometries are the geometries
that correspond to columns of the gene count matrix, such as Visium
spots and cells in datasets from a single cell resolution technology.
Each SFE object can have multiple column geometries. For example, in a
dataset with single cell resolution, whole cell segmentation and nuclei
segmentation are two different colGeometries. However, for
Visium, the spot polygons are the only colGeometry
obviously relevant, though users can add other geometries such as
results of geometric operations on the spot polygons. The different
geometries can be get or set with their names, and “spotPoly” is the
standard name for Visium spot polygons.
# Get Visium spot polygons
(spots <- colGeometry(sfe, "spotPoly"))
#> Simple feature collection with 77 features and 1 field
#> Geometry type: POLYGON
#> Dimension: XY
#> Bounding box: xmin: 5000 ymin: 13000 xmax: 7000 ymax: 15000
#> CRS: NA
#> First 10 features:
#> geometry sample_id
#> AAATTACCTATCGATG POLYGON ((6472.186 13875.23... Vis5A
#> AACATATCAACTGGTG POLYGON ((5778.291 13635.43... Vis5A
#> AAGATTGGCGGAACGT POLYGON ((7000 13809.84, 69... Vis5A
#> AAGGGACAGATTCTGT POLYGON ((6749.535 13874.64... Vis5A
#> AATATCGAGGGTTCTC POLYGON ((5500.941 13636.03... Vis5A
#> AATGATGATACGCTAT POLYGON ((6612.42 14598.82,... Vis5A
#> AATGATGCGACTCCTG POLYGON ((5501.981 14118.62... Vis5A
#> AATTCATAAGGGATCT POLYGON ((6889.769 14598.22... Vis5A
#> ACGAGTACGGATGCCC POLYGON ((5084.397 13395.63... Vis5A
#> ACGCTAGTGATACACT POLYGON ((5639.096 13394.44... Vis5A
plot(st_geometry(spots))
# Set colGeometry
colGeometry(sfe, "spotPoly") <- spotsTo see which colGeometries are present in the SFE
object:
colGeometryNames(sfe)
#> [1] "spotPoly"There are shorthands for some specific column or row geometries. For
example, spotPoly(sfe) is equivalent to
colGeometry(sfe, "spotPoly") shown above.
# Getter
(spots <- spotPoly(sfe))
#> Simple feature collection with 77 features and 1 field
#> Geometry type: POLYGON
#> Dimension: XY
#> Bounding box: xmin: 5000 ymin: 13000 xmax: 7000 ymax: 15000
#> CRS: NA
#> First 10 features:
#> geometry sample_id
#> AAATTACCTATCGATG POLYGON ((6472.186 13875.23... Vis5A
#> AACATATCAACTGGTG POLYGON ((5778.291 13635.43... Vis5A
#> AAGATTGGCGGAACGT POLYGON ((7000 13809.84, 69... Vis5A
#> AAGGGACAGATTCTGT POLYGON ((6749.535 13874.64... Vis5A
#> AATATCGAGGGTTCTC POLYGON ((5500.941 13636.03... Vis5A
#> AATGATGATACGCTAT POLYGON ((6612.42 14598.82,... Vis5A
#> AATGATGCGACTCCTG POLYGON ((5501.981 14118.62... Vis5A
#> AATTCATAAGGGATCT POLYGON ((6889.769 14598.22... Vis5A
#> ACGAGTACGGATGCCC POLYGON ((5084.397 13395.63... Vis5A
#> ACGCTAGTGATACACT POLYGON ((5639.096 13394.44... Vis5A
# Setter
spotPoly(sfe) <- spotsAnnotation
Annotation geometries can be get or set with
annotGeometry(). In column or row geometries, the number of
rows of the sf data frame (i.e. the number of geometries in
the data frame) is constrained by the number of rows or columns of the
gene count matrix respectively, because just like rowData
and colData, each row of a rowGeometry or
colGeometry sf data frame must correspond to a
row or column of the gene count matrix respectively. In contrast, an
annotGeometry sf data frame can have any
dimension, not constrained by the dimension of the gene count
matrix.
# Getter, by name or index
(tb <- annotGeometry(sfe, "tissueBoundary"))
#> Simple feature collection with 1 feature and 2 fields
#> Geometry type: POLYGON
#> Dimension: XY
#> Bounding box: xmin: 5094 ymin: 13000 xmax: 7000 ymax: 14969
#> CRS: NA
#> ID geometry sample_id
#> 7 7 POLYGON ((5094 13000, 5095 ... Vis5A
plot(st_geometry(tb))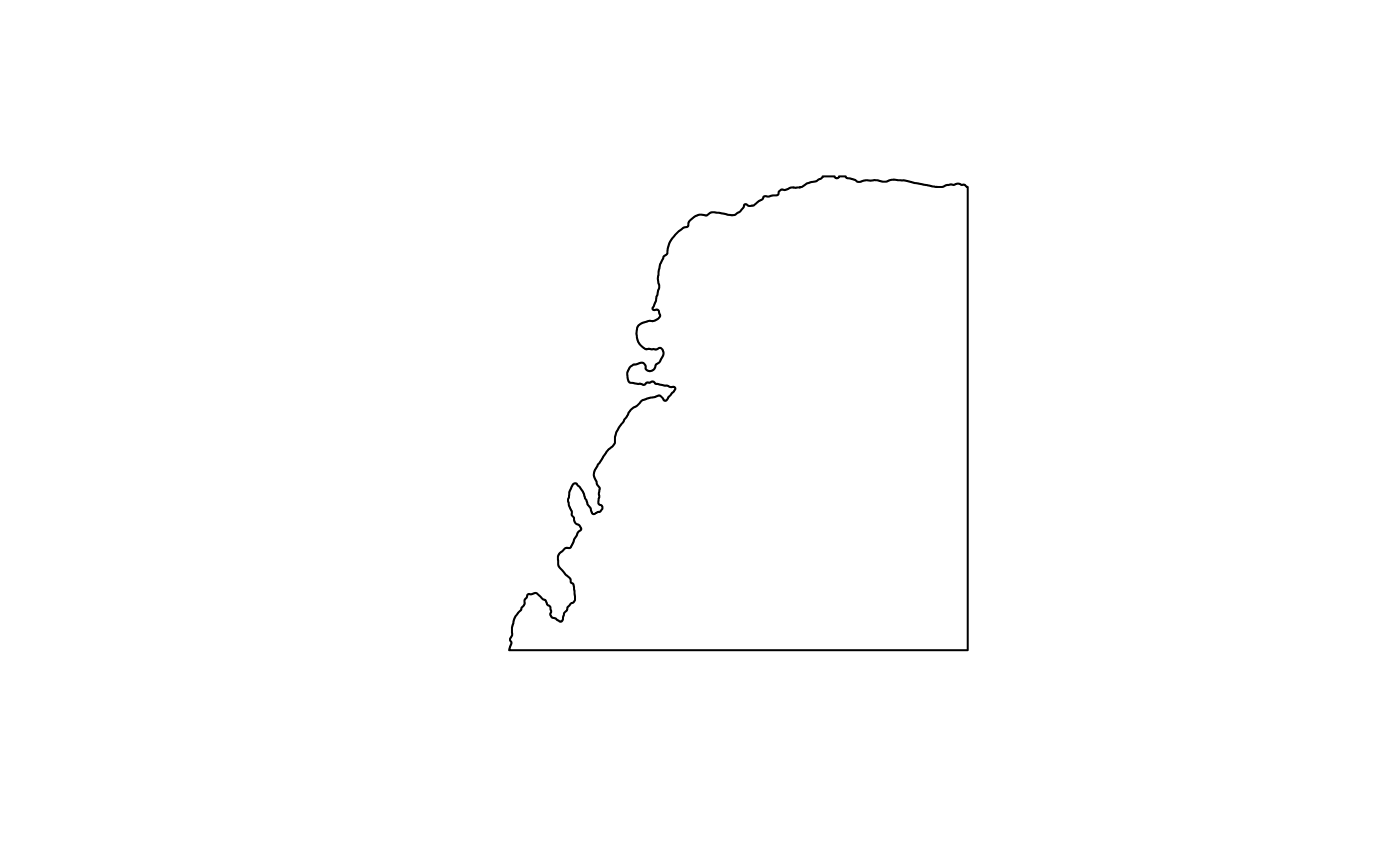
# Setter, by name or index
annotGeometry(sfe, "tissueBoundary") <- tbSee which annotGeometries are present in the SFE
object:
annotGeometryNames(sfe)
#> [1] "tissueBoundary" "myofiber_full" "myofiber_simplified"
#> [4] "nuclei" "nuclei_centroid"There are shorthands for specific annotation geometries. For example,
tissueBoundary(sfe) is equivalent to
annotGeometry(sfe, "tissueBoundary").
cellSeg() (cell segmentation) and nucSeg()
(nuclei segmentation) would first query colGeometries (for
single cell, single molecule technologies, equivalent to
colGeometry(sfe, "cellSeg") or
colGeometry(sfe, "nucSeg")), and if not found, they will
query annotGeometries (for array capture and
microdissection technologies, equivalent to
annotGeometry(sfe, "cellSeg") or
annotGeometry(sfe, "nucSeg")).
# Getter
(tb <- tissueBoundary(sfe))
#> Simple feature collection with 1 feature and 2 fields
#> Geometry type: POLYGON
#> Dimension: XY
#> Bounding box: xmin: 5094 ymin: 13000 xmax: 7000 ymax: 14969
#> CRS: NA
#> ID geometry sample_id
#> 7 7 POLYGON ((5094 13000, 5095 ... Vis5A
# Setter
tissueBoundary(sfe) <- tbSpatial graphs
The spatial neighborhood graphs for Visium spots are stored in the
colGraphs field, which has similar user interface as
colGeometries. SFE also wraps all methods to find the
spatial neighborhood graph implemented in the spdep
package, and triangulation is used here as demonstration.
(g <- findSpatialNeighbors(sfe, MARGIN = 2, method = "tri2nb"))
#> Characteristics of weights list object:
#> Neighbour list object:
#> Number of regions: 77
#> Number of nonzero links: 428
#> Percentage nonzero weights: 7.218755
#> Average number of links: 5.558442
#>
#> Weights style: W
#> Weights constants summary:
#> n nn S0 S1 S2
#> W 77 5929 77 28.0096 309.4083
plot(g, coords = spatialCoords(sfe))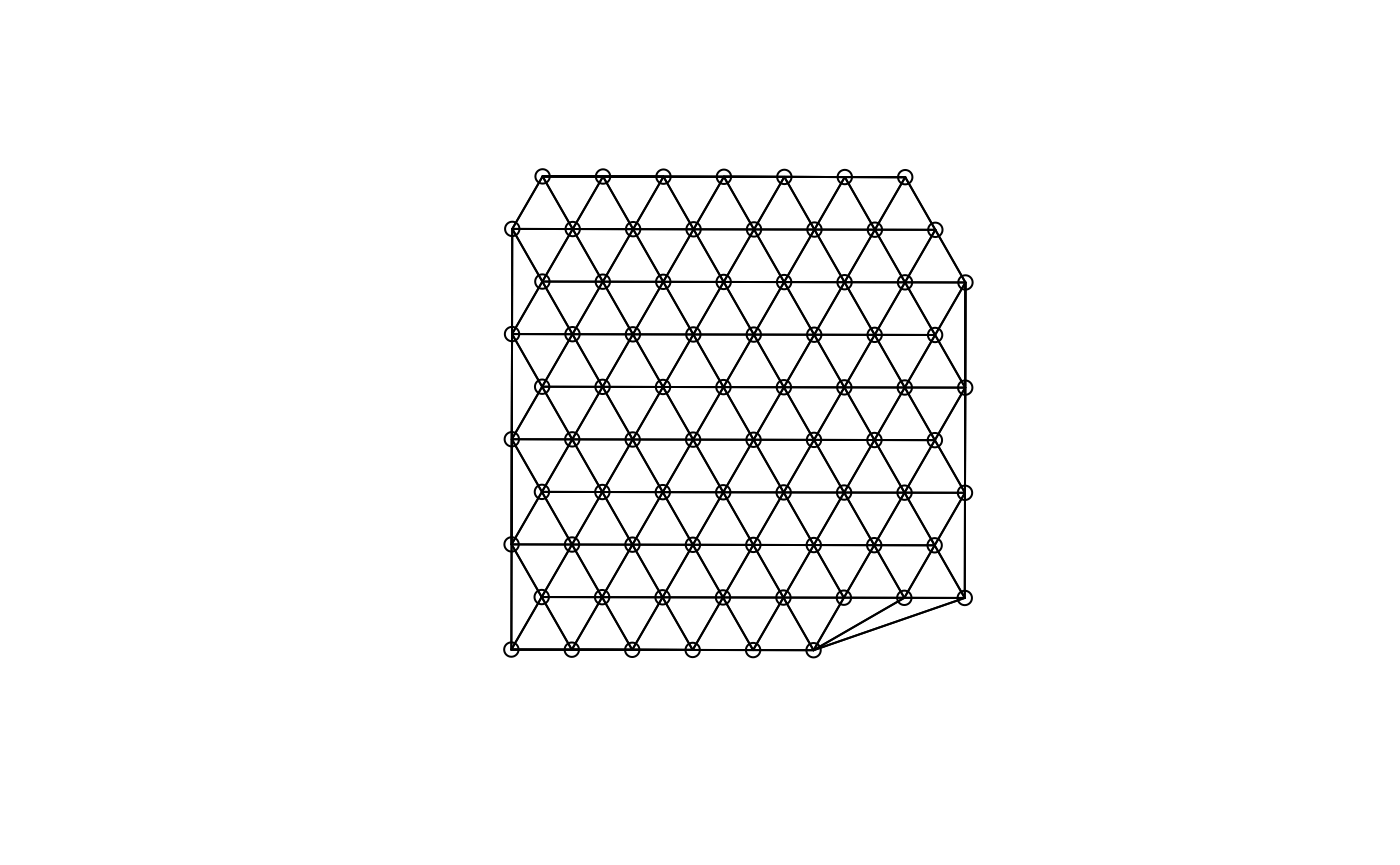
# Set graph by name
colGraph(sfe, "graph1") <- g
# Get graph by name
(g <- colGraph(sfe, "graph1"))
#> Characteristics of weights list object:
#> Neighbour list object:
#> Number of regions: 77
#> Number of nonzero links: 428
#> Percentage nonzero weights: 7.218755
#> Average number of links: 5.558442
#>
#> Weights style: W
#> Weights constants summary:
#> n nn S0 S1 S2
#> W 77 5929 77 28.0096 309.4083For Visium, spatial neighborhood graph of the hexagonal grid can be
found with the known locations of the barcodes. One SFE object can have
multiple colGraphs.
colGraph(sfe, "visium") <- findVisiumGraph(sfe)
plot(colGraph(sfe, "visium"), coords = spatialCoords(sfe))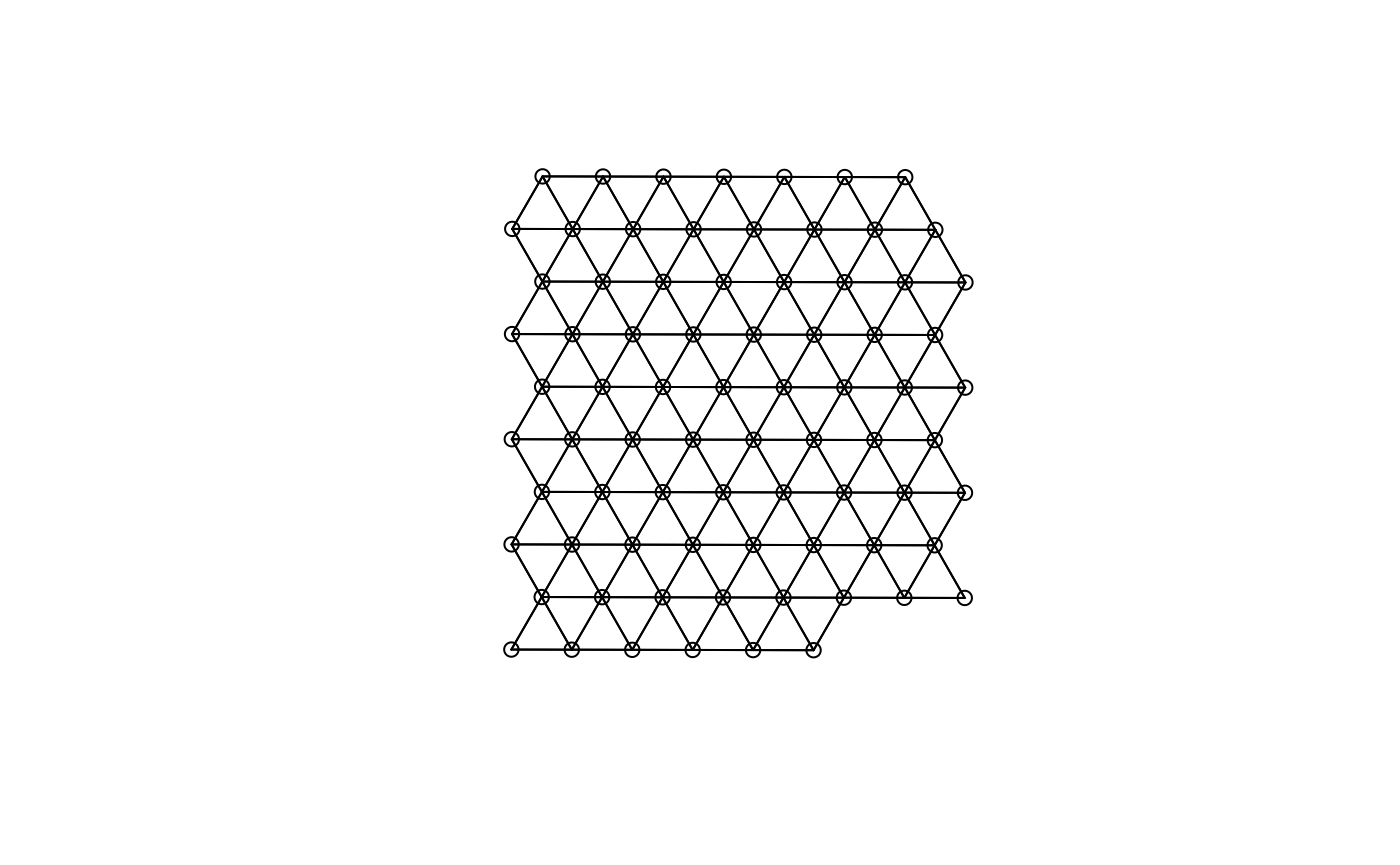
Which graphs are present in this SFE object?
colGraphNames(sfe)
#> [1] "graph1" "visium"While this workshop only works with one sample, i.e. tissue section, operations on multiple samples is discussed in the vignette of the SFE package.
Part 2: Voyager ESDA
Dataset
The dataset used in this vignette is from the paper Large-scale
integration of single-cell transcriptomic data captures transitional
progenitor states in mouse skeletal muscle regeneration (McKellar et al. 2021). Notexin was injected
into the tibialis anterior muscle of mice to induce injury, and the
healing muscle was collected 2, 5, and 7 days post injury for Visium
analysis. The dataset in this vignette is from the timepoint at day 2.
The vignette starts with a SpatialFeatureExperiment (SFE)
object.
The gene count matrix was directly downloaded from
GEO. All 4992 spots, whether in tissue or not, are included. The
H&E image was used for nuclei and myofiber segmentation. A subset of
nuclei from randomly selected regions from all 3 timepoints were
manually annotated to train a StarDist model to segment the rest of the
nuclei, and the myofibers were all manually segmented. The tissue
boundary was found by thresholding in OpenCV, and small polygons were
removed as they are likely to be debris. Spot polygons were constructed
with the spot centroid coordinates and diameter in the Space Ranger
output. The in_tissue column in colData
indicates which spot polygons intersect the tissue polygons, and is
based on st_intersects().
Tissue boundary, nuclei, myofiber, and Visium spot polygons are
stored as sf data frames in the SFE object. See the
vignette of SpatialFeatureExperiment for more details
on the structure of the SFE object. The SFE object of this dataset is
provided in the SFEData package; we begin by downloading
the data and loading it into R.
(sfe <- McKellarMuscleData("full"))
#> see ?SFEData and browseVignettes('SFEData') for documentation
#> loading from cache
#> class: SpatialFeatureExperiment
#> dim: 15123 4992
#> metadata(0):
#> assays(1): counts
#> rownames(15123): ENSMUSG00000025902 ENSMUSG00000096126 ...
#> ENSMUSG00000064368 ENSMUSG00000064370
#> rowData names(6): Ensembl symbol ... vars cv2
#> colnames(4992): AAACAACGAATAGTTC AAACAAGTATCTCCCA ... TTGTTTGTATTACACG
#> TTGTTTGTGTAAATTC
#> colData names(12): barcode col ... prop_mito in_tissue
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
#> spatialCoords names(2) : imageX imageY
#> imgData names(1): sample_id
#>
#> unit: full_res_image_pixels
#> Geometries:
#> colGeometries: spotPoly (POLYGON)
#> annotGeometries: tissueBoundary (POLYGON), myofiber_full (POLYGON), myofiber_simplified (POLYGON), nuclei (POLYGON), nuclei_centroid (POINT)
#>
#> Graphs:
#> Vis5A:The H&E image of this section:

The image can be added to the SFE object and plotted behind the geometries, and needs to be flipped to align to the spots because the origin is at the top left for the image but bottom left for geometries.
sfe <- addImg(sfe, file = "tissue_lowres_5a.jpeg", sample_id = "Vis5A",
image_id = "lowres",
scale_fct = 1024/22208)
sfe <- mirrorImg(sfe, sample_id = "Vis5A", image_id = "lowres")Exploratory data analysis
Spots in tissue
While the example dataset has all Visium spots whether on tissue or not, only spots that intersect tissue are used for further analyses.
names(colData(sfe))
#> [1] "barcode" "col" "row" "x" "y" "dia"
#> [7] "tissue" "sample_id" "nCounts" "nGenes" "prop_mito" "in_tissue"Total UMI counts (nCounts), number of genes detected per
spot (nGenes), and the proportion of mitochondrially
encoded counts (prop_mito) have been precomputed and are in
colData(sfe). The plotSpatialFeature()
function can be used to visualize various attributes in space: the
expression of any gene, colData values, and geometry
attributes in colGeometry and annotGeometry.
The Visium spots are plotted as polygons reflecting their actual size
relative to the tissue, rather than as points, as is the case in other
packages that plot Visium data. The plotting of geometries is being
performed under the hood with geom_sf.
The tissue boundary was found by thresholding the H&E image and
removing small polygons that are most likely debris. The
in_tissue column of colData(sfe) indicates
which Visium spot polygon intersects the tissue polygon; this can be
found with SpatialFeatureExperiment::annotPred().
We demonstrate the use of scran (Lun, Bach, and Marioni 2016) for normalization
below, although we note that it is not necessarily the best approach to
normalizing spatial transcriptomics data. The problem of when and how to
normalize spatial transcriptomics data is non-trivial because, as the
nCounts plot in space shows above, spatial autocorrelation
is evident. Furthermore, in Visium, reverse transcription occurs in situ
on the spots, but PCR amplification occurs after the cDNA is dissociated
from the spots. Artifacts may be subsequently introduced from the
amplification step, and these would not be associated with spatial
origin. Spatial artifacts may arise from the diffusion of transcripts
and tissue permeablization. However, given how the total counts seem to
correspond to histological regions, the total counts may have a
biological component and hence should not be treated as a technical
artifact to be normalized away as in scRNA-seq data normalization
methods. In other words, the issue of normalization for spatial
transcriptomics data, and Visium in particular, is complex and is
currently unsolved.
sfe_tissue <- sfe[,colData(sfe)$in_tissue]
sfe_tissue <- sfe_tissue[rowSums(counts(sfe_tissue)) > 0,]
#clusters <- quickCluster(sfe_tissue)
#sfe_tissue <- computeSumFactors(sfe_tissue, clusters=clusters)
#sfe_tissue <- sfe_tissue[, sizeFactors(sfe_tissue) > 0]
sfe_tissue <- logNormCounts(sfe_tissue)Myofiber and nuclei segmentation polygons are available in this
dataset in the annotGeometries field. Myofibers were
manually segmented, and nuclei were segmented with StarDist
trained with a manually segmented subset.
annotGeometryNames(sfe_tissue)
#> [1] "tissueBoundary" "myofiber_full" "myofiber_simplified"
#> [4] "nuclei" "nuclei_centroid"From myofibers and nuclei to Visium spots
The plotSpatialFeature() function can also be used to
plot attributes of geometries, i.e. the non-geometry columns in the
sf data frames in the rowGeometries,
colGeometries, or annotGeometries fields of
the SFE object.
The myofiber polygons from annotGeometries can be
plotted as shown below, colored by cross section area as observed in the
tissue section. The aes_use argument is set to
color rather than fill (default for polygons)
to only plot the Visium spot outlines to make the myofiber polygons more
visible. The fill argument is set to NA to
make the Visium spots look hollow, and the size argument
controls the thickness of the outlines. The annot_aes
argument specifies which column in the annotGeometry to use
to specify the values of an aesthstic, just like aes in
ggplot2 (aes_string to be precise, since
tidyeval is not used here). The annot_fixed
argument (not used here) can set the fixed size, alpha, color, and etc.
for the annotGeometry.
plotSpatialFeature(sfe_tissue, features = "nCounts",
colGeometryName = "spotPoly",
annotGeometryName = "myofiber_simplified",
aes_use = "color", linewidth = 0.5, fill = NA,
annot_aes = list(fill = "area"))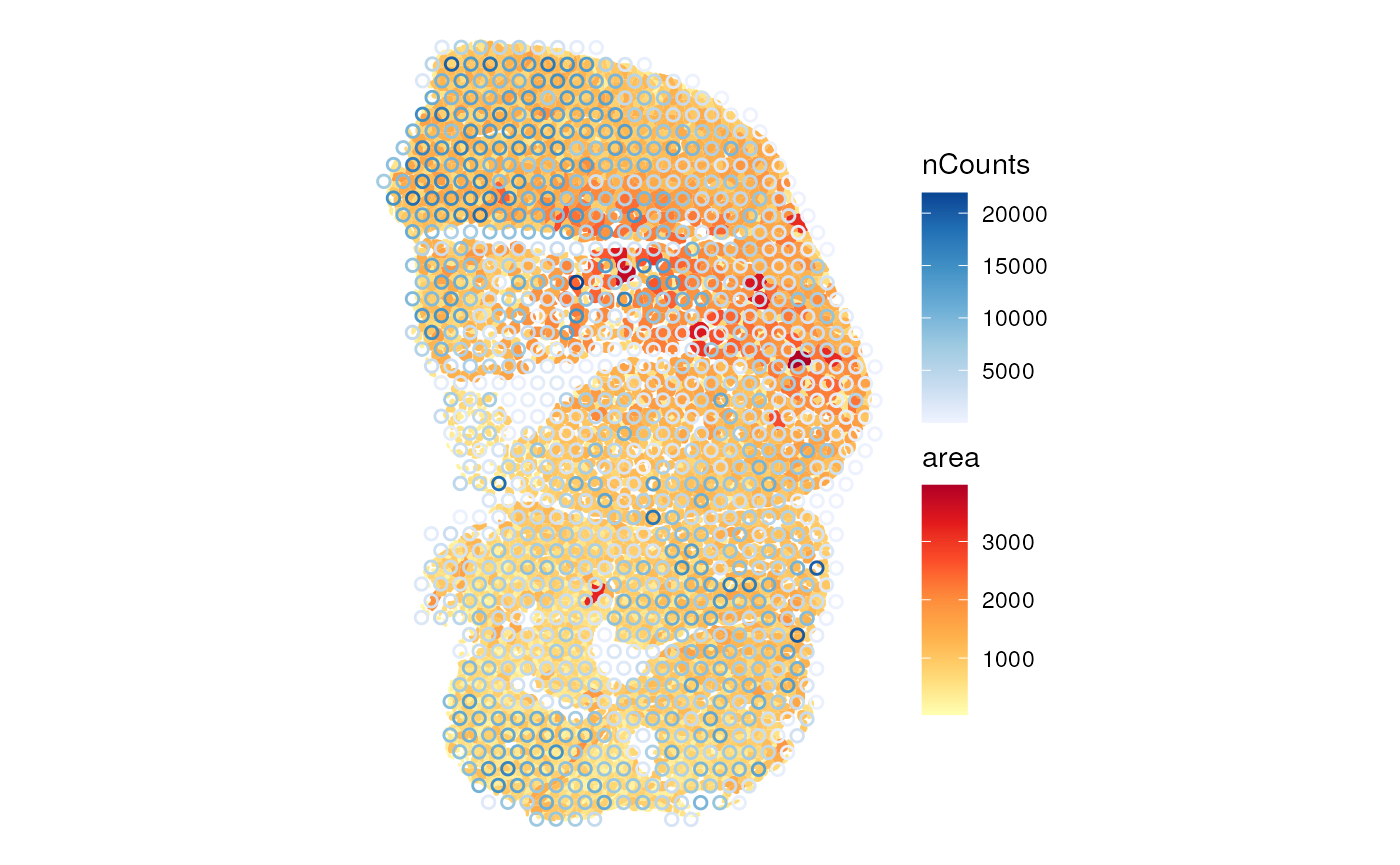
The larger myofibers seem to have fewer total counts, possibly because the larger size of these myofibers dilutes the transcripts. This hints at the need for a normalization procedure.
With SpatialFeatureExperiment, we can find the number of
myofibers and nuclei that intersect each Visium spot. The predicate can
be anything
implemented in sf, so for example, the number of nuclei
fully covered by each Visium spot can also be found. The default
predicate is st_intersects().
colData(sfe_tissue)$n_myofibers <-
annotNPred(sfe_tissue, colGeometryName = "spotPoly",
annotGeometryName = "myofiber_simplified")
plotSpatialFeature(sfe_tissue, features = "n_myofibers",
colGeometryName = "spotPoly", image = "lowres", color = "black",
linewidth = 0.1)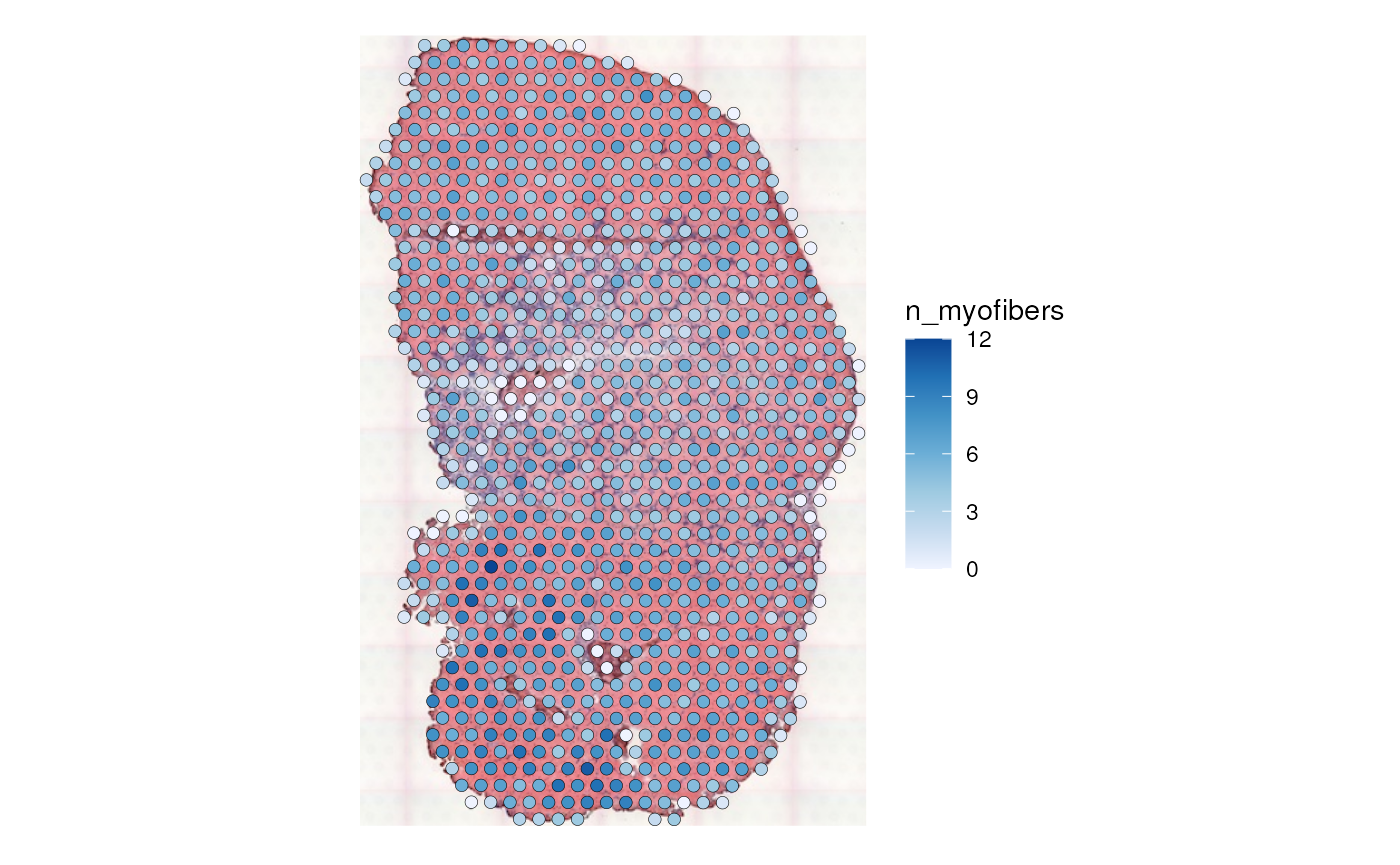
There is no one-to-one mapping between Visium spots and myofibers.
However, we can relate attributes of myofibers to gene expression
detected at the Visium spots. One way to do so is to summarize the
attributes of all myofibers that intersect (or choose another better
predicate implemented in sf) each spot, such as to
calculate the mean, median, or sum. This can be done with the
annotSummary() function in
SpatialFeatureExperiment. The default predicate is
st_intersects(), and the default summary function is
mean().
colData(sfe_tissue)$mean_myofiber_area <-
annotSummary(sfe_tissue, "spotPoly", "myofiber_simplified",
annotColNames = "area")[,1] # it always returns a data frame
# The gray spots don't intersect any myofiber
plotSpatialFeature(sfe_tissue, "mean_myofiber_area", "spotPoly", image = "lowres",
color = "black", linewidth = 0.1)
This reveals the relationship between the mean area of myofibers intersecting each Visium spot and other aspects of the spots, such as total counts and gene expression.
The NAs (gray) designate spots not intersecting any myofibers, e.g. those in the inflammatory region.
The nGenes vs. nCounts plot is a standard QC plot in scRNA-seq, but here we see two mysterious branches and two clusters in the nGenes vs. nCounts plot and the proportion of mitochondrial counts vs. nCounts plot. The two branches or clusters seem to be related to myofiber size.
plotColData(sfe_tissue, x = "nCounts", y = "nGenes", colour_by = "mean_myofiber_area")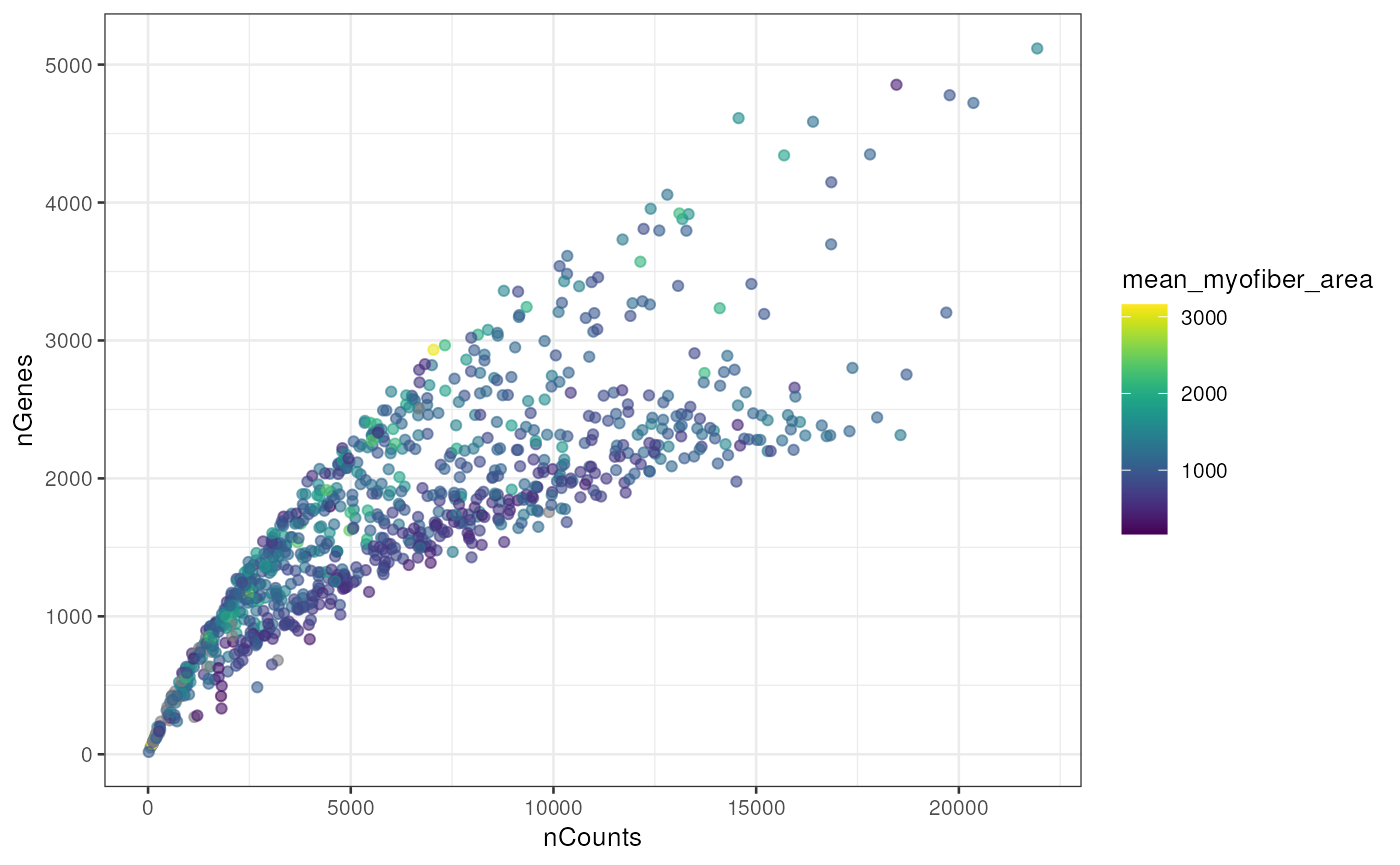
plotColData(sfe_tissue, x = "nCounts", y = "prop_mito", colour_by = "mean_myofiber_area")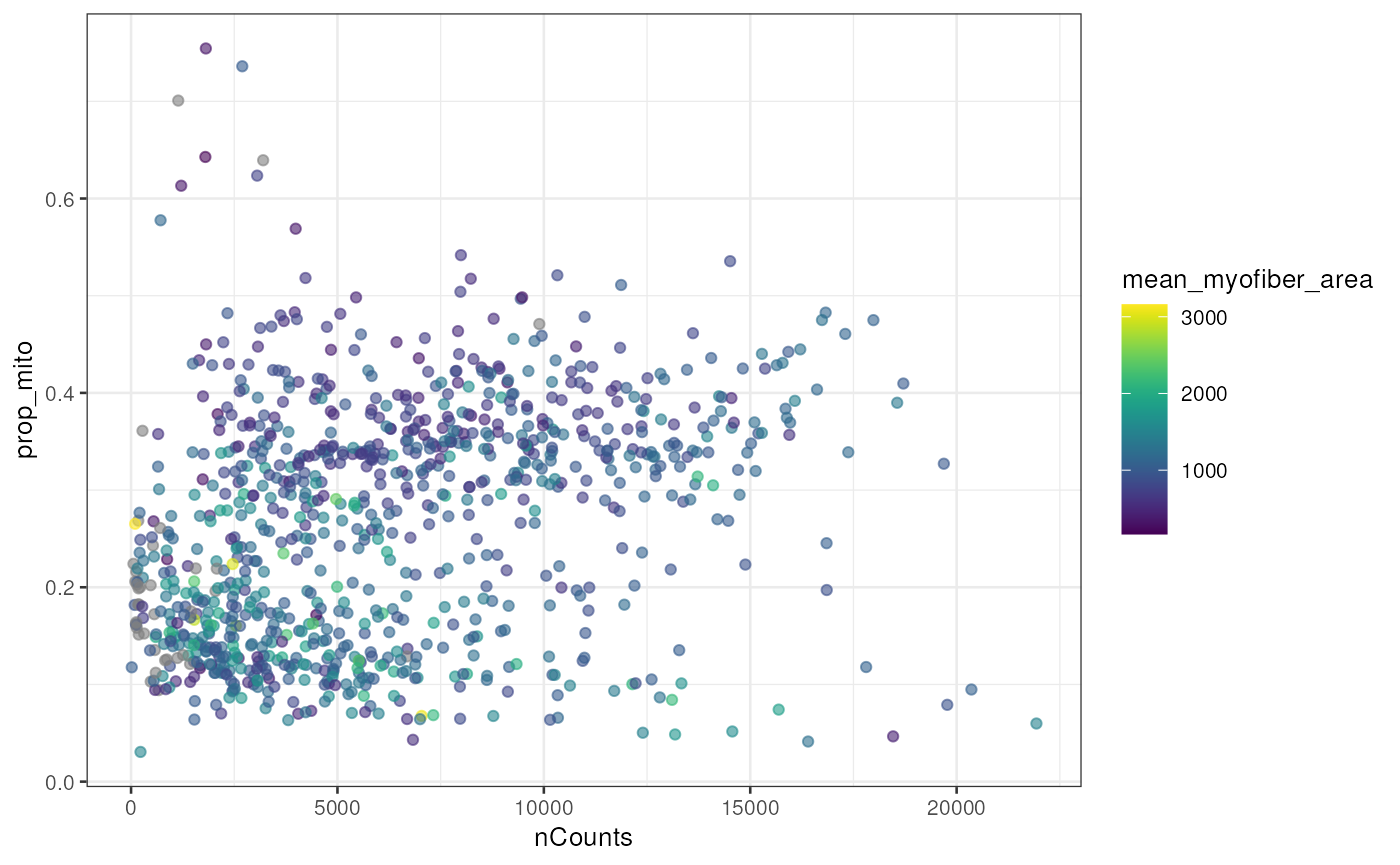
Exercises
- Use the
annotNPred()function to find the number of nuclei intersecting each Visium spot. The nuclei segmentation polygons are in theannotGeometrycalled “nuclei”. - Color the Visium spots with the number of nuclei. Which histological region tends to have more nuclei per Visium spot?
- Does the number of nuclei per spot correlate with nCounts?
Plot gene expression in space
Marker genes: Myh7 (Type I, slow twitch, aerobic), Myh2 (Type IIa, fast twitch, somewhat aerobic), Myh4 (Type IIb, fast twitch, anareobic), Myh1 (Type IIx, fast twitch, anaerobic), from this protocol (Wang, Yue, and Kuang 2017)
markers <- c(I = "Myh7", IIa = "Myh2", IIb = "Myh4", IIx = "Myh1")We first examine the Type I myofibers. This is a fast twitch muscle,
so we don’t expect many slow twitch Type I myofibers. Row names in
sfe_tissue are Ensembl IDs in order to avoid ambiguity as
sometimes multiple Ensembl IDs have the same gene symbol and some genes
have aliases. However, gene symbols are shorter and more human readable
than Ensembl IDs, and are better suited to display on plots. In the
plotSpatialFeature() function and other functions in
Voyager, even when the row names are recorded as Ensembl
IDs, the features argument can take gene symbols if when a
column in rowData(sfe) that has the gene symbols are
supplied in the swap_rownames argument. All function in
Voyager that queries genes has the
swap_rownames argument.
plotSpatialFeature(sfe_tissue, "Myh2", "spotPoly",
annotGeometryName = "myofiber_simplified",
annot_aes = list(fill = "area"), swap_rownames = "symbol",
exprs_values = "logcounts", aes_use = "color", linewidth = 0.5,
fill = NA)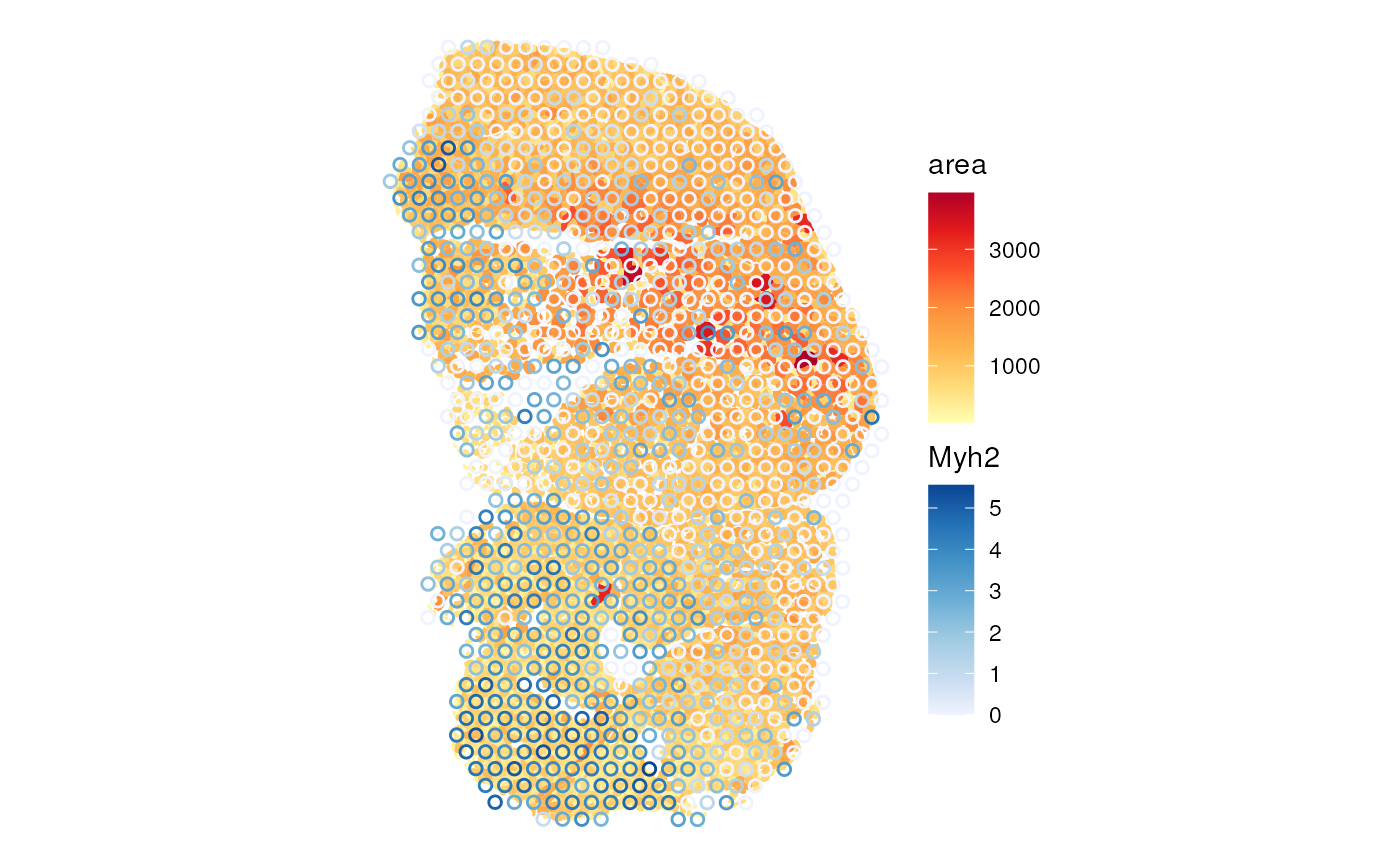
Exercises
- The
exprs_valuesargument specifies the assay to use, which is by default “logcounts”, i.e. the log normalized data. This default may or may not be suitable in practice given that total UMI counts may have biological relevance in spatial data. Plot one of the marker genes above, but with the “counts” assay. - Look up the documentation of
plotSpatialFeature(). Try plotting the Visium spots as filled circles that are partially transparent.
Spatial neighborhood graphs
A spatial neighborhood graph is required to compute spatial
dependency metrics such as Moran’s I and Geary’s C. The
SpatialFeatureExperiment package wraps methods in
spdep to find spatial neighborhood graphs, which are stored
within the SFE object (see spdep documentation for
gabrielneigh(), knearneigh(),
poly2nb(), and tri2nb()). The
Voyager package then uses these graphs for spatial
dependency analyses, again based on spdep in this first
version, but methods from other geospatial packages, some of which also
use the spatial neighborhood graphs, may be added later.
For Visium, where the spots are in a hexagonal grid, the spatial
neighborhood graph is straightforward. However, for spatial technologies
with single cell resolution, e.g. MERFISH, different methods can be used
to find the spatial neighborhood graph. In this example, the method
“poly2nb” was used for myofibers, and it identifies myofiber polygons
that physically touch each other. zero.policy = TRUE will
allow for singletons, i.e. nodes without neighbors in the graph; in the
inflamed region, there are more singletons. We have not yet benchmarked
spatial neighborhood construction methods to determine which is the
“best” for different technologies; the particular method used here is
for demonstration purposes and may not be the best in practice:
colGraph(sfe_tissue, "visium") <- findVisiumGraph(sfe_tissue)
annotGraph(sfe_tissue, "myofiber_poly2nb") <-
findSpatialNeighbors(sfe_tissue, type = "myofiber_simplified", MARGIN = 3,
method = "poly2nb", zero.policy = TRUE)The plotColGraph() function plots the graph in space
associated with a colGeometry, along with the geometry of
interest.
plotColGraph(sfe_tissue, colGraphName = "visium", colGeometryName = "spotPoly") +
theme_void()
Similarly, the plotAnnotGraph() function plots the graph
associated with an annotGeometry, along with the geometry
of interest.
plotAnnotGraph(sfe_tissue, annotGraphName = "myofiber_poly2nb",
annotGeometryName = "myofiber_simplified") + theme_void()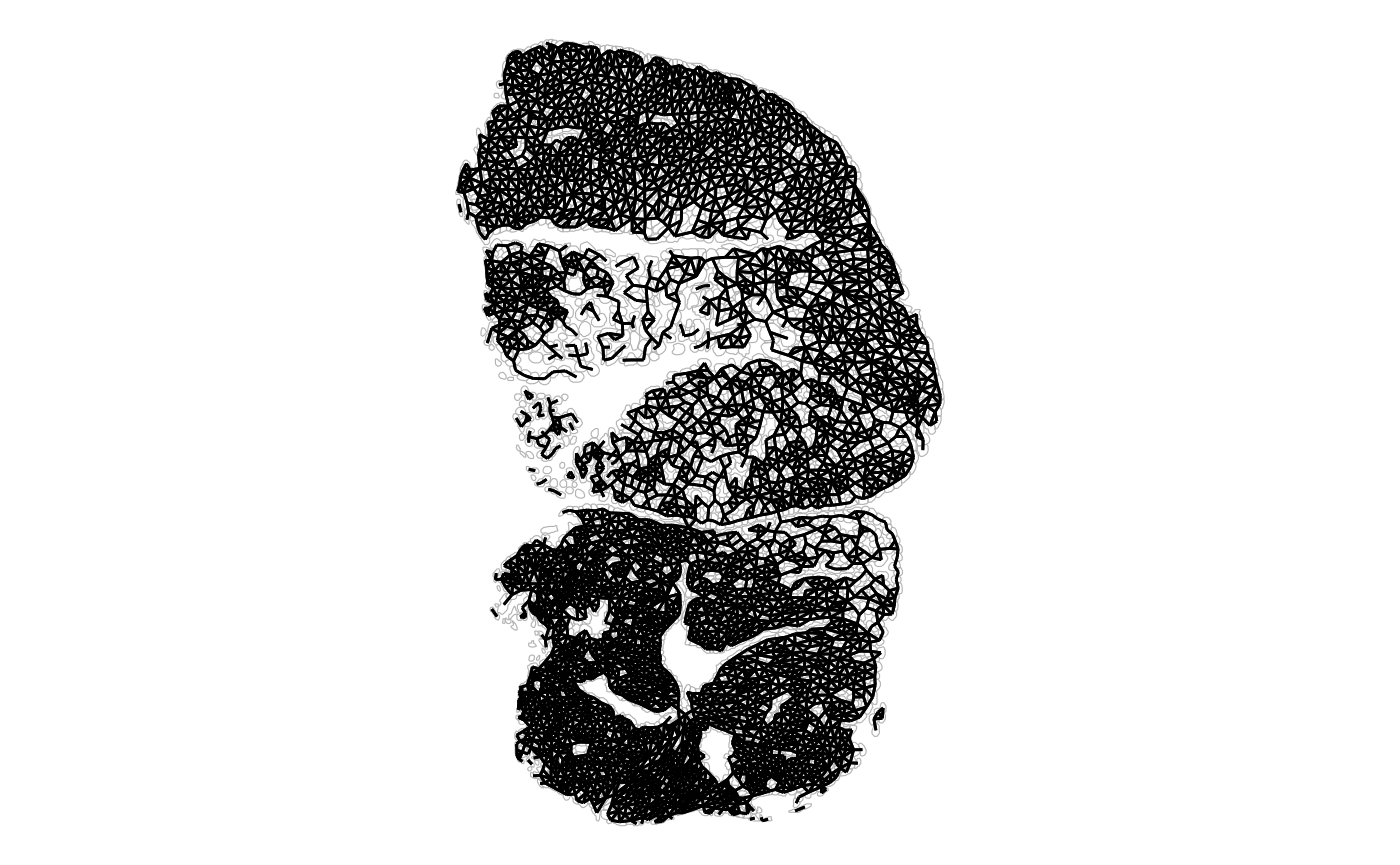
There is no plotRowGraph yet since we haven’t worked
with a dataset where spatial graphs related to genes are relevant,
although the SFE object supports row graphs.
Exploratory spatial data analysis
All spatial autocorrelation metrics in this package can be computed
directly on a vector or a matrix rather than an SFE object. The user
interface emulates those of dimension reductions in the
scater package (e.g. calculateUMAP() that
takes in a matrix or SCE object and returns a matrix, and
runUMAP() that takes in an SCE object and adds the results
to the reducedDims field of the SCE object). So
calculate* functions take in a matrix or an SFE object and
directly return the results (format of the results depends on the
structure of the results), while run* functions take in an
SFE object and add the results to the object. In addition,
colData* functions compute the metrics for numeric
variables in colData. colGeometry* functions
compute the metrics for numeric columns in a colGeometry.
annotGeometry* functions compute the metrics for numeric
columns in a annotGeometry.
Univariate global
Voyager supports many univariate global spatial
autocorrelation implemented in spdep for ESDA: Moran’s I
and Geary’s C, permutation testing for Moran’s I and Geary’s C, Moran
plot, and correlograms. In addition, beyond spdep,
Voyager can cluster Moran plots and correlograms. Plotting
functions taking in SFE objects are implemented to plot the results with
ggplot2 and with more customization options than
spdep plotting functions. The functions
calculateUnivariate() (can take data outside SFE objects),
runUnivariate() (for gene expression),
colDataUnivariate(), colGeometryUnivariate(),
annotGeometryUnivariate(), and
reducedDimUnivariate() compute univariate spatial
statistics for different fields of the SFE object, and they all have the
same arguments except for arguments specific to the field of the SFE
object. The argument type, which indicates the
corresponding function names in spdep, determines which
spatial statistics are computed.
All univariate global methods in Voyager are listed
here:
listSFEMethods(variate = "uni", scope = "global")
#> name description
#> 1 moran Moran's I
#> 2 geary Geary's C
#> 3 moran.mc Moran's I with permutation testing
#> 4 geary.mc Geary's C with permutation testing
#> 5 sp.mantel.mc Mantel-Hubert spatial general cross product statistic
#> 6 moran.test Moran's I test
#> 7 geary.test Geary's C test
#> 8 globalG.test Global G test
#> 9 sp.correlogram Correlogram
#> 10 variogram Variogram with model
#> 11 variogram_map Variogram mapWhen calling calculate*variate() or
run*variate(), the type (2nd) argument takes a
string that matches an entry in the name column in the data
frame returned by listSFEMethods().
To demonstrate spatial autocorrelation in gene expression, top highly
variable genes (HVGs) are used. The HVGs are found with the
scran method.
dec <- modelGeneVar(sfe_tissue)
hvgs <- getTopHVGs(dec, n = 50)A global statistic yields one result for the entire dataset.
Moran’s I
As a reference, Pearson correlation is defined as
\[ \rho_{X,Y} = \frac{\sum_{i=1}^n\sum_{j=1}^n (x_i - \bar x)(y_i - \bar y)}{\sqrt{\sum_{i=1}^n (x_i - \bar x)^2}\sqrt{\sum_{i=1}^n (y_i - \bar y)^2}}. \]
There are several ways to quantify spatial autocorrelation, the most common of which is Moran’s I (Moran 1950):
\[ I = \frac{n}{\sum_{i=1}^n \sum_{j=1}^n w_{ij}} \frac{\sum_{i=1}^n \sum_{j=1}^n w_{ij} (x_i - \bar{x})(x_j - \bar{x})}{\sum_{i=1}^n (x_i - \bar{x})^2}, \]
where \(n\) is the number of spots
or locations, \(i\) and \(j\) are different locations, or spots in
the Visium context, \(x\) and \(y\) are variables with values at each
location, and \(w_{ij}\) is a spatial
weight, which can be inversely proportional to distance between spots or
an indicator of whether two spots are neighbors, subject to various
definitions of neighborhood and whether to normalize the number of
neighbors. The spdep
package uses the neighborhood.
Moran’s I is analogous to the Pearson correlation between the value at each location and the average value at its neighbors (but not identical, see (Lee 2001)). Just like Pearson correlation, Moran’s I is generally bound between -1 and 1, where positive value indicates positive spatial autocorrelation, i.e. nearby values tend to be more similar, and negative value indicates negative spatial autocorrelation, i.e. nearby values tend to be more dissimilar.
Upon visual inspection earlier in the workshop, total UMI counts per
spot (nCounts) seem to have spatial autocorrelation. For numeric columns
of colData(sfe), all univariate methods can be called with
colDataUnivariate(). Here we compute Moran’s I for nCounts
and nGenes:
sfe_tissue <- colDataUnivariate(sfe_tissue, type = "moran",
features = c("nCounts", "nGenes"),
colGraphName = "visium")
colFeatureData(sfe_tissue)[c("nCounts", "nGenes"),]
#> DataFrame with 2 rows and 2 columns
#> moran_Vis5A K_Vis5A
#> <numeric> <numeric>
#> nCounts 0.528705 3.00082
#> nGenes 0.384028 3.88036For colData, the results are added to
colFeatureData(sfe), and features for which Moran’s I is
not calculated have NA. The column names of featureData
distinguishes between different samples (there’s only one sample in this
dataset), and are parsed by plotting functions. Here the first column is
the Moran’s I value, which indicates moderate positive spatial
autocorrelation for both nCounts and nGenes. The second column is
kurtosis of the data.
Compute Moran’s I for attributes of geometries: Here “area” is the area of the cross section of each myofiber as seen in this tissue section and “eccentricity” is the eccentricity of the ellipse fitted to each myofiber.
# Remember zero.policy = TRUE since there're singletons
sfe_tissue <- annotGeometryUnivariate(sfe_tissue, type = "moran",
features = c("area", "eccentricity"),
annotGeometryName = "myofiber_simplified",
annotGraphName = "myofiber_poly2nb",
zero.policy = TRUE)
attr(annotGeometry(sfe_tissue, "myofiber_simplified"), "featureData")[c("area", "eccentricity"),]
#> DataFrame with 2 rows and 2 columns
#> moran_Vis5A K_Vis5A
#> <numeric> <numeric>
#> area 0.327888 4.95675
#> eccentricity 0.110938 3.26913For a non-geometry column in a colGeometry,
colGeometryUnivariate() is like
annotGeometryUnivariate() here, but none of the
colGeometries in this dataset has extra columns.
For gene expression, the logcounts assay is used by
default (use the exprs_values argument to change the
assay), though this may or may not be best practice. If the metrics are
computed for a large number of features, parallel computing is
supported, with BiocParallel,
with the BPPARAM argument.
sfe_tissue <- runUnivariate(sfe_tissue, type = "moran", features = hvgs,
colGraphName = "visium", BPPARAM = SerialParam())
rowData(sfe_tissue)[head(hvgs),c("moran_Vis5A", "K_Vis5A", "symbol")]
#> DataFrame with 6 rows and 3 columns
#> moran_Vis5A K_Vis5A symbol
#> <numeric> <numeric> <character>
#> ENSMUSG00000029304 0.734937 1.63516 Spp1
#> ENSMUSG00000050708 0.665563 1.81841 Ftl1
#> ENSMUSG00000050335 0.741474 1.68098 Lgals3
#> ENSMUSG00000021939 0.708362 1.86896 Ctsb
#> ENSMUSG00000021190 0.659916 1.66838 Lgmn
#> ENSMUSG00000018893 0.675840 1.82510 MbAs Moran’s I is very commonly used,
runMoransI(sfe_tissue, features = hvgs) is equivalent to
runUnivariate(sfe_tissue, type = "moran", features = hvgs).
Exercises
- Use
listSFEMethods()to find the “name” of Geary’s C (Geary 1954). This name should be used in thetypeargument inrunUnivariate(). - Compute Geary’s C on the highly variable genes, and show the results. Interpretation of Geary’s C: a value below 1 indicates positive spatial autocorrelation, while a value above 1 indicates negative spatial autocorrelation.
Further reading
- Spatial transcriptomics data is usually much larger than the typical geospatial dataset back in the 1950s when Moran’s I and Geary’s C were devised. See (Luo, Griffith, and Wu 2019) for asymptotic properties of Moran’s I for large datasets with normal and skewed distributions.
- The negative binomial distribution is often used to model transcriptomics data due to bursts in transcription, although the Poisson distribution is sometimes used instead to simplify the math. See (Griffith and Haining 2006) for a consideration of the Poisson distribution in spatial analyses.
- Moran’s I is not exactly the same as Pearson correlation between the values themselves and the spatially smoothed values. The bounds of Moran’s I depend on the spatial neighborhood graph. Usually the upper bound is around 1, while the lower bound is closer to -0.5 than -1. See (Jong, Sprenger, and Veen 1984) for a derivation of extreme values of Moran’s I and Geary’s C.
- Spatial autocorrelation decays at different length scales for different features, and the correlogram is one way to find the length scales. These are the vignettes that use correlograms. Also see this vignette on Moran’s I flipping signs at different length scales.
Univariate local
Local statistics yield a result at each location rather than the
whole dataset, while global statistics may obscure local heterogeneity.
See (Fotheringham 2009) for an interesting
discussion of relationships between global and local spatial statistics.
Local statistics are stored in the localResults field of
the SFE object, which can be accessed by the localResult()
or localResults() functions in the
SpatialFeatureExperiment package.
All univariate local methods in Voyager are listed
here:
listSFEMethods(variate = "uni", scope = "local")
#> name description
#> 1 localmoran Local Moran's I
#> 2 localmoran_perm Local Moran's I permutation testing
#> 3 localC Local Geary's C
#> 4 localC_perm Local Geary's C permutation testing
#> 5 localG Getis-Ord Gi(*)
#> 6 localG_perm Getis-Ord Gi(*) with permutation testing
#> 7 LOSH Local spatial heteroscedasticity
#> 8 LOSH.mc Local spatial heteroscedasticity permutation testing
#> 9 LOSH.cs Local spatial heteroscedasticity Chi-square test
#> 10 moran.plot Moran scatter plotLocal Moran’s I
To recap, global Moran’s I is defined as
\[ I = \frac{n}{\sum_{i=1}^n \sum_{j=1}^n w_{ij}} \frac{\sum_{i=1}^n \sum_{j=1}^n w_{ij} (x_i - \bar{x})(x_j - \bar{x})}{\sum_{i=1}^n (x_i - \bar{x})^2}. \]
Local Moran’s I (Anselin 1995) is defined as
\[ I_i = (n-1)\frac{(x_i - \bar{x})\sum_{j=1}^n w_{ij} (x_j - \bar{x})}{\sum_{i=1}^n (x_i - \bar{x})^2}. \]
It’s similar to global Moran’s I, but the values at locations \(i\) are not summed and there’s no normalization by the sum of spatial weights. Local Moran’s I has been used in spatial transcriptomics in the MERINGUE package (Miller et al. 2021). Here we compute local Moran’s I for the gene Myh2.
sfe_tissue <- runUnivariate(sfe_tissue, type = "localmoran", features = "Myh2",
colGraphName = "visium", swap_rownames = "symbol")It is useful to plot the log normalized Myh2 gene expression as context to interpret the local results:
plotSpatialFeature(sfe_tissue, features = "Myh2", colGeometryName = "spotPoly",
swap_rownames = "symbol", image_id = "lowres", color = "black",
linewidth = 0.1)
Any local spatial results can be plotted with
plotLocalResults(), which is similar to
plotSpatialFeature(). Here a divergent palette is used
because Moran’s I has a sensible center at 0 (actually the expected
value of Moran’s I is -1/(n-1) when the mean is unknown, but it’s very
close to 0 as n is typically large in spatial -omics).
plotLocalResult(sfe_tissue, "localmoran", features = "Myh2",
colGeometryName = "spotPoly", divergent = TRUE,
diverge_center = 0, image_id = "lowres",
swap_rownames = "symbol", color = "black",
linewidth = 0.1)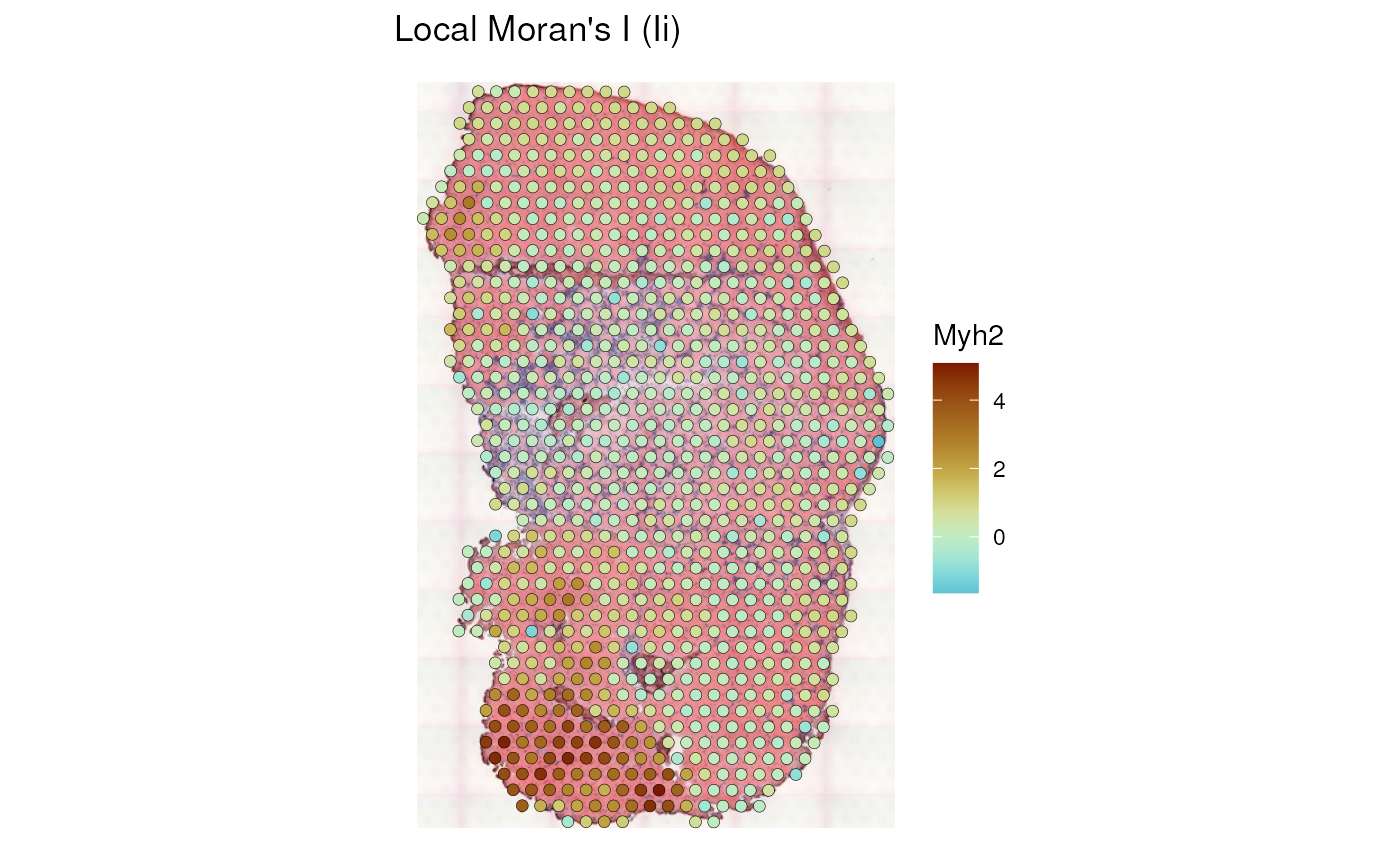
We see that myofiber regions with higher Myh2 expression also have stronger spatial autocorrelation, while the injury site locally has some negative spatial autocorrelation.
The results are stored in the localResults field in the
SFE object, with getters and setters analogous to
reducedDims, but the name of the local method and the
feature/gene for which the local method was run need to be specified as
well.
lr <- localResult(sfe_tissue, type = "localmoran", feature = "Myh2",
swap_rownames = "symbol")
head(lr)
#> Ii E.Ii Var.Ii Z.Ii Pr(z != E(Ii))
#> AAACATTTCCCGGATT 2.12545883 -0.0012237995 0.37891181 3.45488511 5.505274e-04
#> AAACCTAAGCAGCCGG 3.33088903 -0.0038553468 0.59334776 4.32920244 1.496503e-05
#> AAACGAGACGGTTGAT 0.30430735 -0.0009817045 0.15152269 0.78428227 4.328745e-01
#> AAACGGGCGTACGGGT 4.69775712 -0.0063342069 0.97242481 4.77032239 1.839313e-06
#> AAACTCGGTTCGCAAT 0.01991573 -0.0002817611 0.04351933 0.09681804 9.228709e-01
#> AAACTGCTGGCTCCAA 0.55285063 -0.0009817045 0.15152269 1.42278566 1.547983e-01
#> mean median pysal -log10p -log10p_adj
#> AAACATTTCCCGGATT High-High High-High High-High 3.25922109 2.657161
#> AAACCTAAGCAGCCGG High-High High-High High-High 4.82492235 3.979824
#> AAACGAGACGGTTGAT Low-Low Low-Low Low-Low 0.36363800 0.000000
#> AAACGGGCGTACGGGT High-High High-High High-High 5.73534434 4.890246
#> AAACTCGGTTCGCAAT High-High High-High High-High 0.03485905 0.000000
#> AAACTGCTGGCTCCAA Low-Low Low-Low Low-Low 0.81023381 0.000000It is interesting to see how spatial autocorrelation relates to gene expression level, much as finding how variance relates to mean in the expression of each gene, which usually indicates overdispersion compared to Poisson in scRNA-seq and Visium data:
df <- data.frame(myh2 = logcounts(sfe_tissue)[rowData(sfe_tissue)$symbol == "Myh2",],
Ii = localResult(sfe_tissue, "localmoran", "Myh2",
swap_rownames = "symbol")[,"Ii"])
ggplot(df, aes(myh2, Ii)) + geom_point(alpha = 0.3) +
geom_vline(xintercept = mean(df$myh2), linetype = 2, color = "gray") +
geom_hline(yintercept = 0, linetype = 2, color = "gray") +
labs(x = "Myh2 (log counts)", y = "localmoran")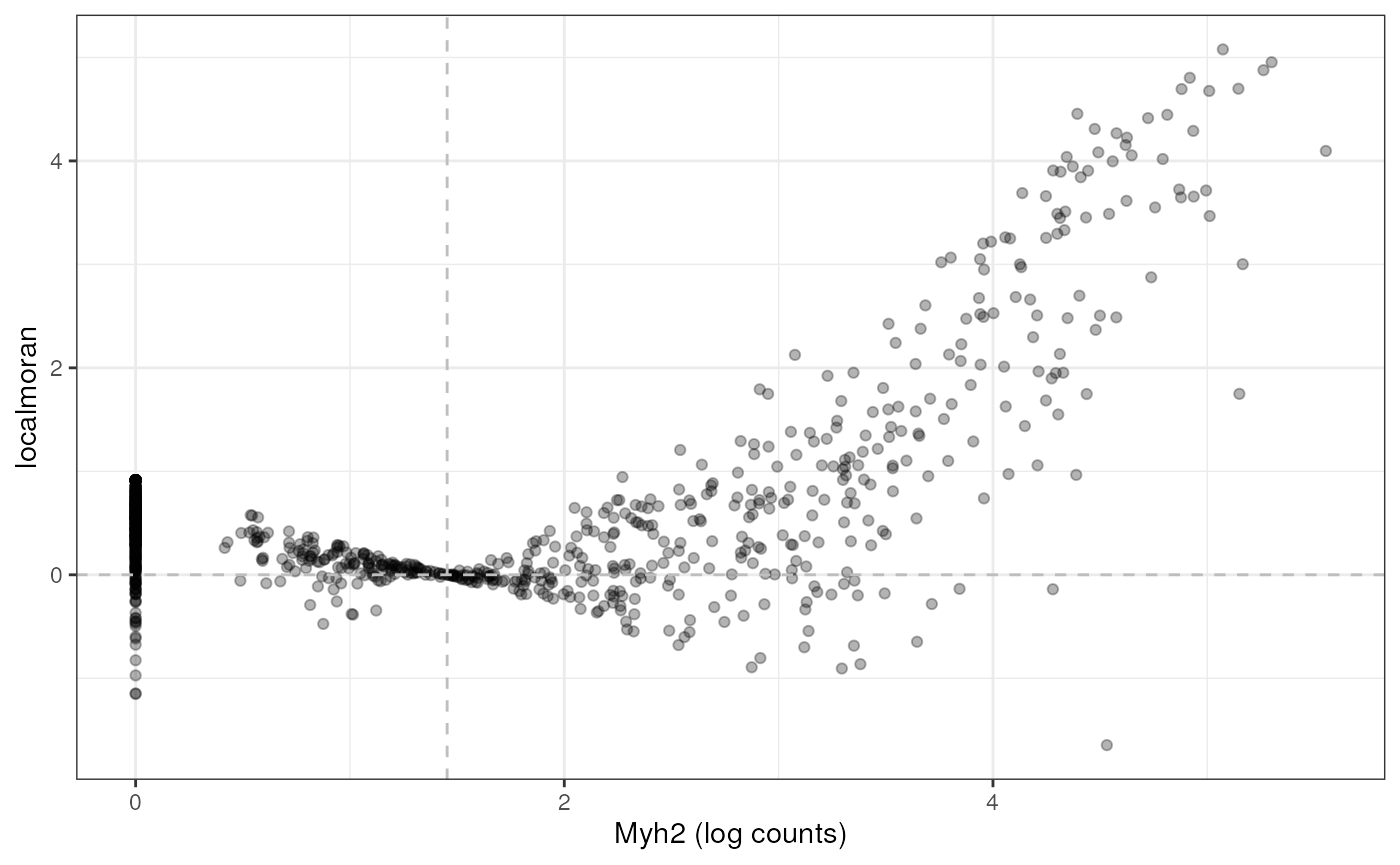
For this gene, Visium spots with higher expression also tend to have higher local Moran’s I, but this may or may not apply to other genes. The vertical dashed line marks the mean gene expression; note the subtraction of mean in the expression for global and local Moran’s I, leading spots close to mean to have local Moran’s I close to 0.
Local spatial analyses often return a matrix or data frame. The
plotLocalResult() function has a default column for each
local spatial method, but other columns can be plotted as well. Use the
localResultAttrs() function to see which columns are
present, and use the attribute argument to specify which
column to plot.
localResultAttrs(sfe_tissue, "localmoran", "Myh2", swap_rownames = "symbol")
#> [1] "Ii" "E.Ii" "Var.Ii" "Z.Ii"
#> [5] "Pr(z != E(Ii))" "mean" "median" "pysal"
#> [9] "-log10p" "-log10p_adj"Some local spatial methods return p-values at each location, in a
column with name like Pr(z != E(Ii)), where the test is two
sided (default, can be changed with the alternative
argument in runUnivariate() which is passed to the relevant
underlying function in spdep). Negative log of the p-value
is computed to facilitate visualization (smaller or more significant
p-values are plotted as higher values), and the p-value is corrected for
multiple hypothesis testing with p.adjustSP() in
spdep, where the number of tests is the number of neighbors
of each location rather than the total number of locations
(-log10p_adj).
plotLocalResult(sfe_tissue, "localmoran", features = "Myh2",
colGeometryName = "spotPoly", attribute = "-log10p_adj", divergent = TRUE,
diverge_center = -log10(0.05), swap_rownames = "symbol",
image_id = "lowres", color = "black",
linewidth = 0.1)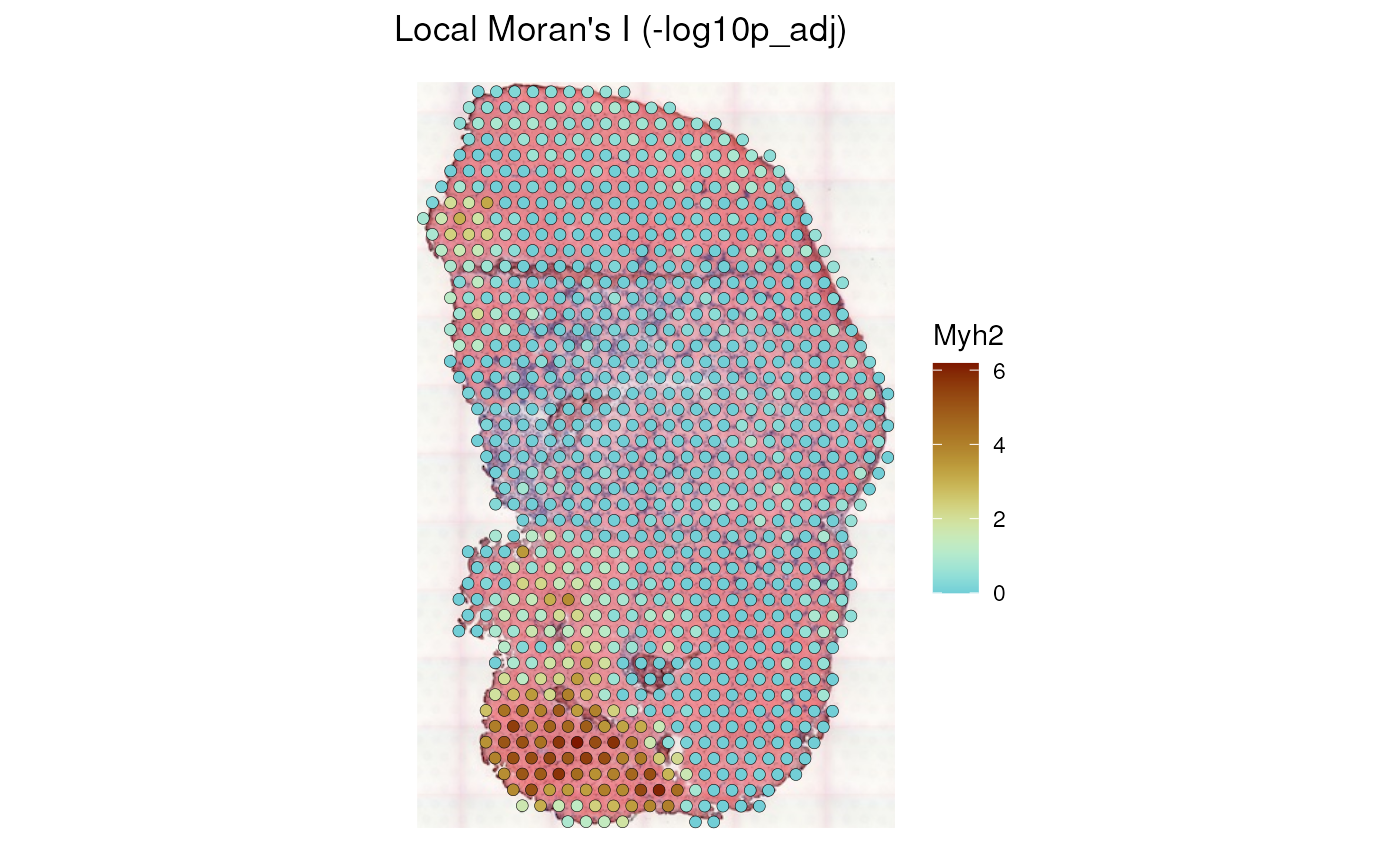
In this plot and all following plots of p-values, a divergent palette is used to show locations that are significant after adjusting for multiple testing and those that are not significant in different colors. The center of the divergent palette is p = 0.05, so the brown spots are significant while a dark blue means really not significant.
The “pysal” column shows the type of neighborhood, such as whether low value is near other low values, or high value is near other high values.
plotLocalResult(sfe_tissue, "localmoran", features = "Myh2",
colGeometryName = "spotPoly", attribute = "pysal",
swap_rownames = "symbol", image_id = "lowres", color = "black",
linewidth = 0.1)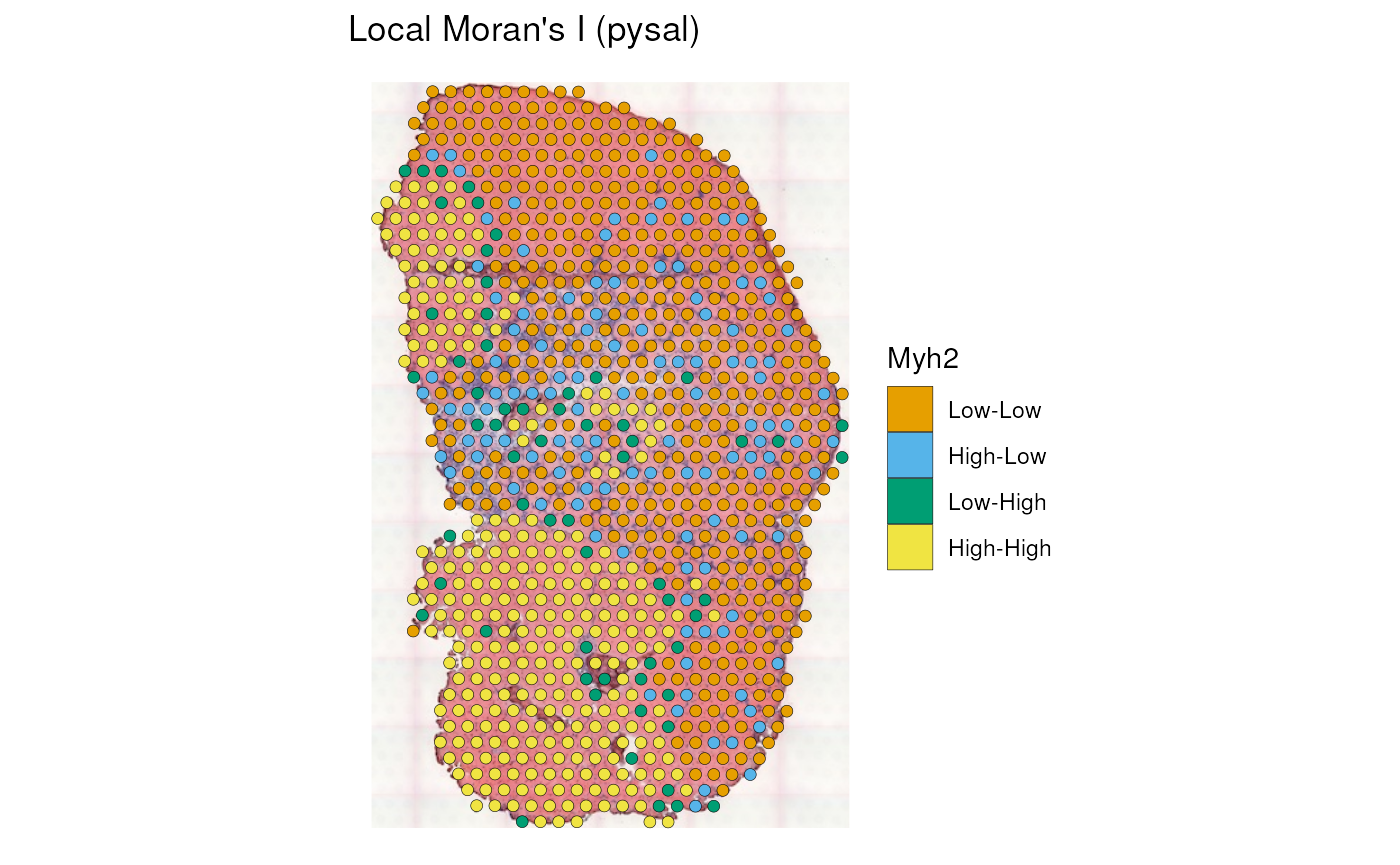
Exercises
- Compute local spatial heteroscedasticity (LOSH) (J. Keith Ord and Getis 2012) on Myh2 and plot the results. A sequential palette is appropriate.
- Which other columns are returned by LOSH? Plot one of them in space.
See documentation of
spdep::LOSH()for the meanings of the other columns. - How does the spatial pattern of LOSH compare to that of local Moran for the same genes?
Further reading
- Getis-Ord Gi* (J. K. Ord and Getis 1995) is another commonly used local spatial statistic which identifies hotspots (high values clustered together in space) and coldspots (low values clostered in space). These vignettes use Getis-Ord Gi*.
- The Moran scatter plot (Anselin 1996) is another ESDA tool.
Voyagerhas a special function to plot the resultsmoranPlot(). See these vignettes for examples of Moran scatter plot applied to spatial transcriptomics. - Analogous to the Moran scatter plot is the Geary scatter plot (not
yet implemented in
Voyager) proposed in (Griffith and Chun 2022) which is said to better detect local negative spatial autocorrelation. This paper also includes other considerations on Moran’s I and Geary’s C.
Bivariate
Some spatial methods analyze how two variables relate. A list of all bivariate global methods can be seen here:
listSFEMethods(variate = "bi", scope = "global")
#> name description
#> 1 lee Lee's bivariate statistic
#> 2 lee.mc Lee's bivariate static with permutation testing
#> 3 lee.test Lee's L test
#> 4 cross_variogram Cross variogram
#> 5 cross_variogram_map Cross variogram mapThere are also local bivariate methods:
listSFEMethods(variate = "bi", scope = "local")
#> name description
#> 1 locallee Local Lee's bivariate statistic
#> 2 localmoran_bv Local bivariate Moran's ILee’s L
Lee’s L (Lee 2001) was developed from relating Moran’s I to Pearson correlation, and is defined as
\[ L_{X,Y} = \frac{n}{\sum_{i=1}^n \sum_{j=1}^n w_{ij}} \frac{\sum_{i=1}^n \left[ \sum_{j=1}^n w_{ij} (x_j - \bar{x}) \right] \left[ \sum_{j=1}^n w_{ij} (y_j - \bar{y}) \right]}{\sqrt{\sum_{i=1}^n (x_i - \bar{x})^2}\sqrt{\sum_{i=1}^n (y_i - \bar{y})^2} }, \]
where \(n\) is the number of spots
or locations, \(i\) and \(j\) are different locations, or spots in
the Visium context, \(x\) and \(y\) are variables with values at each
location, and \(w_{ij}\) is a spatial
weight, which can be inversely proportional to distance between spots or
an indicator of whether two spots are neighbors, subject to various
definitions of neighborhood. The Giotto package has
implemented something like Lee’s L (Dries et al.
2021).
Here we compute Lee’s L for top highly variagle genes (HVGs) in this dataset:
hvgs <- getTopHVGs(sfe_tissue, fdr.threshold = 0.01)Because bivariate global results can have very different formats
(matrix for Lee’s L and lists for many other methods), the results are
not stored in the SFE object. The calculateBivariate()
function is used to perform all bivariate analyses. Analogous to
runUnivariate() there is runBivariate() which
stores the results in the SFE object, but it only applies to local
bivariate methods whose results have a more uniform format and are
stored in the localResults field just like local univariate
results.
res <- calculateBivariate(sfe_tissue, type = "lee", feature1 = hvgs)This gives a spatially informed correlation matrix among the genes, which can be plotted as a heatmap:
pal_rng <- getDivergeRange(res)
pal <- scico(256, begin = pal_rng[1], end = pal_rng[2], palette = "vik")
pheatmap(res, color = pal, show_rownames = FALSE,
show_colnames = FALSE, cellwidth = 1, cellheight = 1,
treeheight_col = 0, treeheight_row = 0)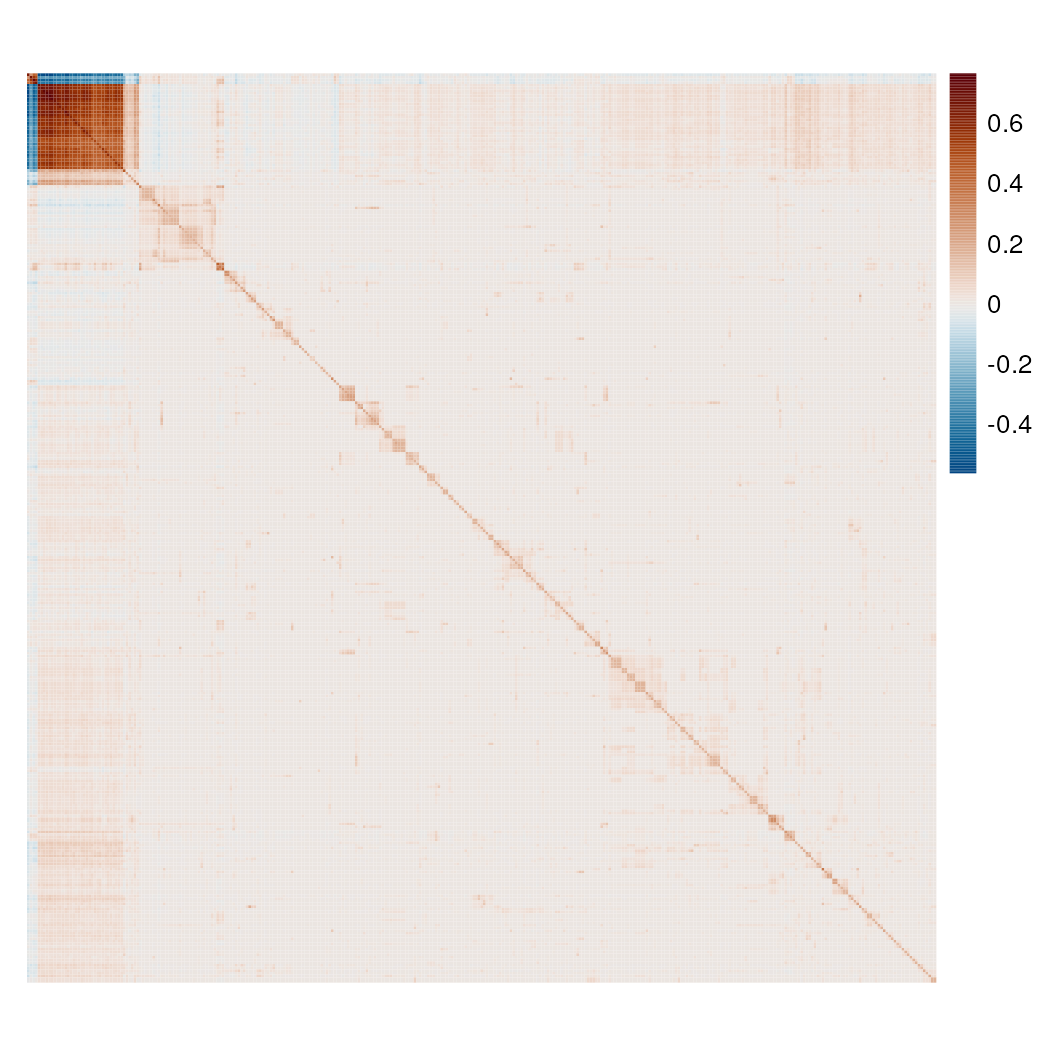
Some coexpression blocks can be seen. Note that unlike in Pearson correlation, the diagonal is not 1, because
\[ L_{X,X} = \frac{\sum_i (\tilde x_i - \bar x)^2}{\sum_i (x_i - \bar x)^2} = \mathrm{SSS}_X, \]
which is approximated the ratio between the variance of spatially lagged \(x\) and variance of \(x\). Because the spatial lag introduces smoothing, the spatial lag reduced variance, making the diagonal less than 1. This is the spatial smoothing scalar (SSS), and Moran’s I is approximately Pearson correlation between \(X\) and spatially lagged \(X\) (\(\tilde X\)) multiplied by SSS:
\[ I \approx \mathrm{SSS}_X \cdot \rho_{X, \tilde X} \]
Similarly for Lee’s L, as shown in (Lee 2001),
\[ L_{X, Y} = \sqrt{\mathrm{SSS}_X}\sqrt{\mathrm{SSS}_Y} \cdot \rho_{\tilde X, \tilde Y} \]
With more spatial clustering, the variance is less reduced by the spatial lag, leading to a larger SSS. Hence when both \(X\) and \(Y\) are spatially distributed like salt and pepper while strongly correlated, Lee’s L will be low because the lack of spatial autocorrelation leads to a small SSS.
Weighted correlation network analysis (WGCNA) (Langfelder and Horvath 2008) is a time honored method to find gene co-expression modules, and it can take any correlation matrix. Then it would be interesting to apply WGCNA to the Lee’s L matrix to identify spatially informed gene co-expression modules.
Exercises
Local Lee’s L is analogous to local Moran’s I – a disaggregated form of Lee’s L showing the contribution of each spot to the global Lee’s L. This is derived in (Lee 2001) after global Lee’s L is shown.
Run local Lee’s L on two genes of your choice. You can use the
myofiber type marker genes Myh7, Myh2, Myh4, and Myh1. Then plot the
results in space. Hint: Use localResultFeatures() to find
what name the results are stored under. How would you interpret the
results?
See this vignette on bivariate methods in Voyager applied to this dataset, including local Lee’s L and a bivariate version of local Moran’s I.
Multivariate
Spatial transcriptomics data can have anywhere from hundreds of genes
to the whole genome. It would be tedious to manually check univariate
spatial statistics one gene at a time. Furthermore, genes are often
co-regulated, while univariate spatial statistics is blind to the
co-regulation. Hence we have multivariate spatial statistics, analyzing
multiple genes simultaneously while taking spatial information into
account. Multivariate spatial methods in Voyager are listed
here:
listSFEMethods("multi")
#> name description
#> 1 multispati MULTISPATI PCA
#> 2 localC_multi Multivariate local Geary's C
#> 3 localC_perm_multi Multivariate local Geary's C permutation testingNon-spatial PCA
First we run regular principal component analysis (PCA), to compare to a type of spatially informed PCA known as MULTISPATI PCA (Stéphane Dray, Saı̈d, and Débias 2008).
hvgs2 <- getTopHVGs(dec, n = 2000)
sfe_tissue <- runPCA(sfe_tissue, ncomponents = 20, subset_row = hvgs2,
exprs_values = "logcounts", scale = TRUE,
BSPARAM = IrlbaParam())Use the elbow plot to see variance explained by each PC:
ElbowPlot(sfe_tissue)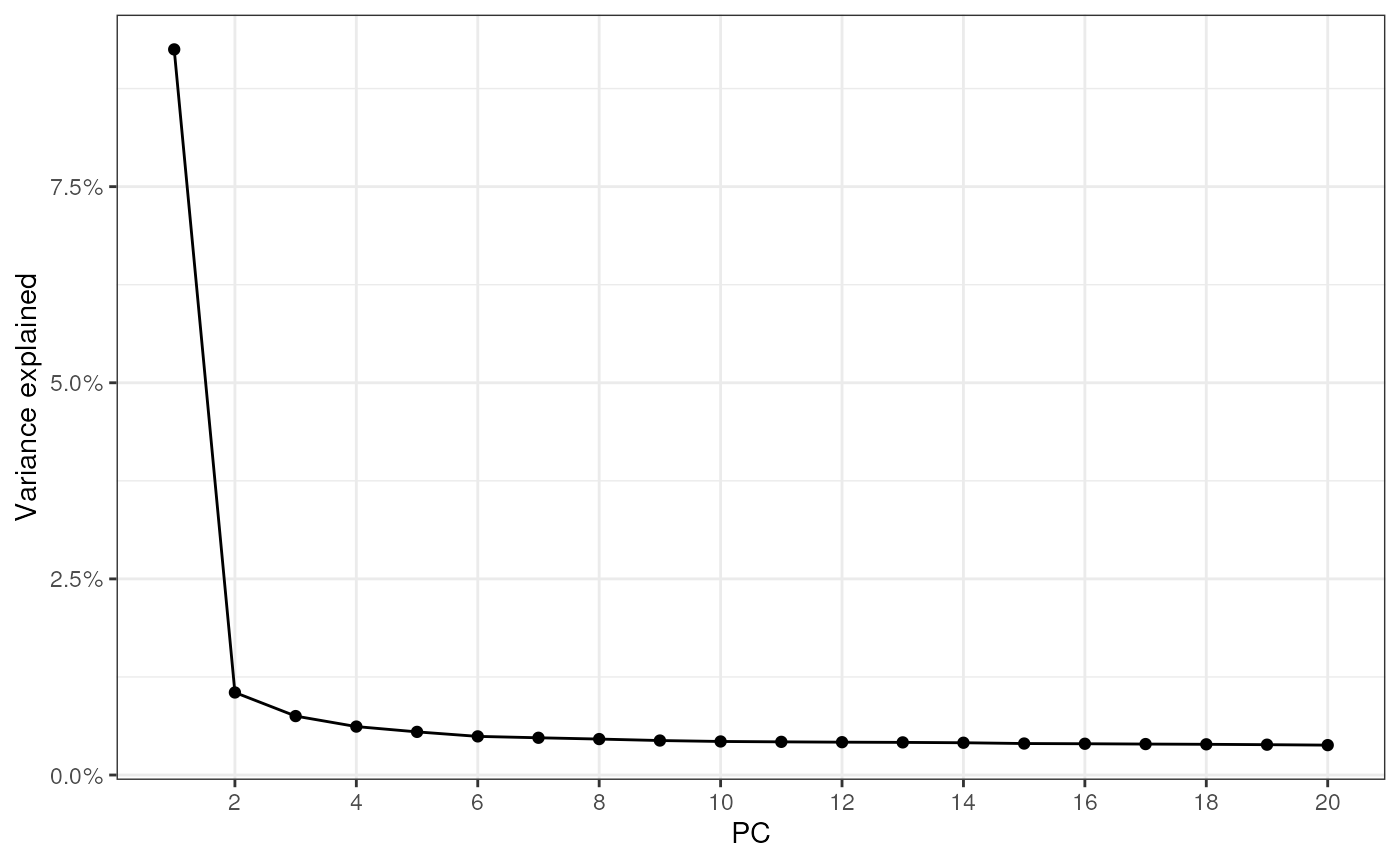
Plot top gene loadings in each PC, which are the contribution of each gene to each PC:
plotDimLoadings(sfe_tissue, swap_rownames = "symbol")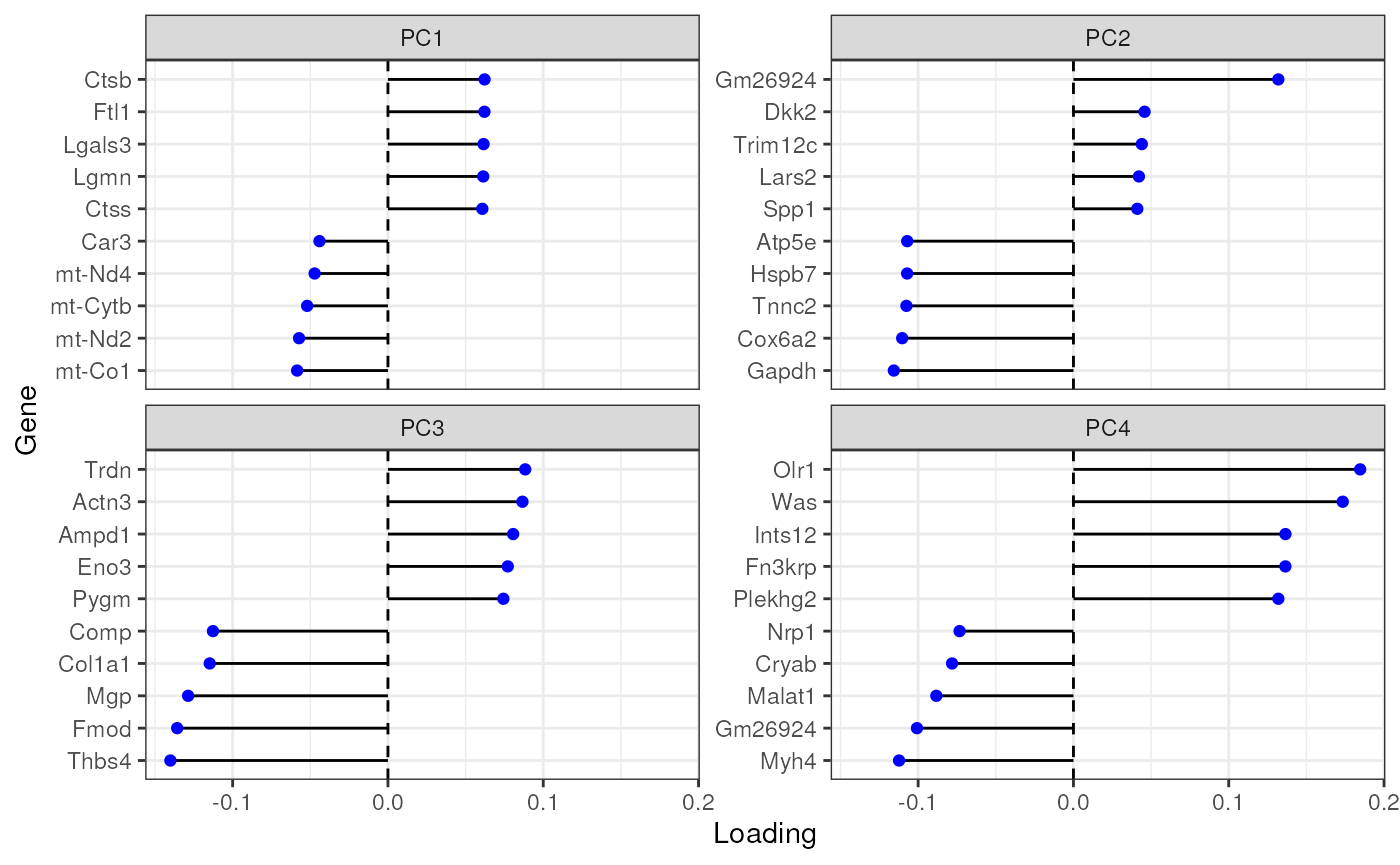
Plot the first 4 PCs in space
spatialReducedDim(sfe_tissue, "PCA", 4, divergent = TRUE, diverge_center = 0,
image_id = "lowres")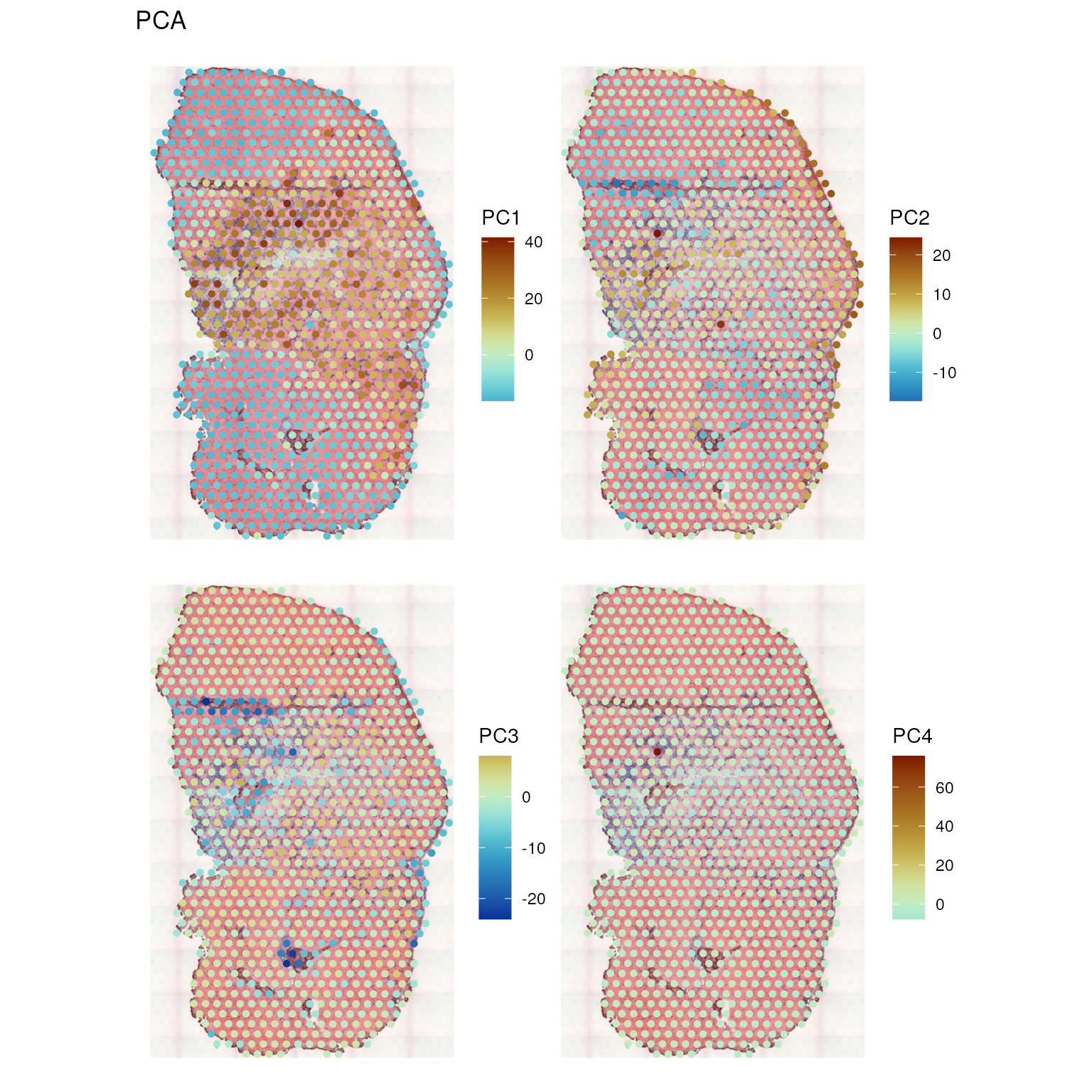
The first PC separates the leukocyte infiltrated injury site from the myofibers, while PC2 and PC3 tease out the muscle tendon junctions.
MULTISPATI PCA
Spatially informed dimension reduction is actually not new, and dates
back to at least 1985, with Wartenberg’s crossover of Moran’s I and PCA
(Wartenberg 1985), which was generalized and
further developed as MULTISPATI PCA (Stéphane Dray, Saı̈d, and Débias 2008),
implemented in the adespatial
package on CRAN. In short, while PCA tries to maximize the variance
explained by each PC, MULTISPATI maximizes the product of Moran’s I and
variance explained. Also, while all the eigenvalues from PCA are
non-negative, because the covariance matrix is positive semidefinite,
MULTISPATI can give negative eigenvalues, which represent negative
spatial autocorrelation, which can be present and interesting but is not
as common as positive spatial autocorrelation and is often masked by the
latter (Griffith 2019).
In single cell -omics conventions, let \(X\) denote a gene count matrix whose columns are cells or Visium spots and whose rows are genes, with \(n\) columns. Let \(W\) denote the row normalized \(n\times n\) adjacency matrix of the spatial neighborhood graph of the cells or Visium spots, which does not have to be symmetric. MULTISPATI diagonalizes a symmetric matrix
\[ H = \frac 1 {2n} X(W^t+W)X^t \]
However, the implementation in adespatial is more
general and can be used for other multivariate analyses in the duality
diagram paradigm, such as correspondence analysis; the equation
above is simplified just for PCA, without having to introduce the
duality diagram here.
Here we compute MULTISPATI PCA, with the 20 most positive and 20 most negative eigenvalues.
sfe_tissue <- runMultivariate(sfe_tissue, "multispati", colGraphName = "visium",
nfposi = 20, nfnega = 20, subset_row = hvgs2)Then plot the most positive and most negative eigenvalues. Note that the eigenvalues here are not variance explained. Instead, they are the product of variance explained and Moran’s I. So the most positive eigenvalues correspond to eigenvectors that simultaneously explain more variance and have large positive Moran’s I. The most negative eigenvalues correspond to eigenvectors that simultaneously explain more variance and have negative Moran’s I.
ElbowPlot(sfe_tissue, nfnega = 20, reduction = "multispati")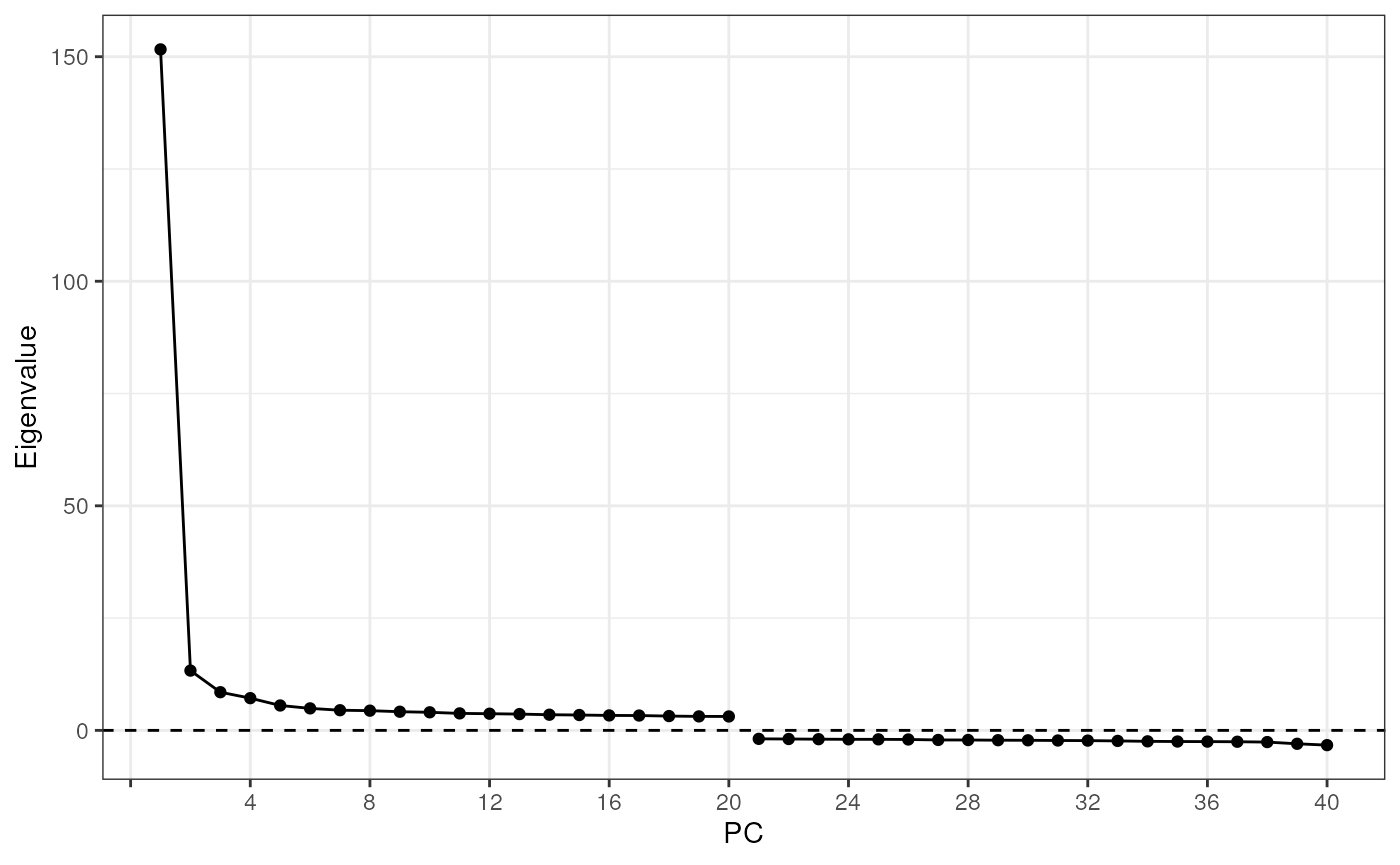
Here the positive eigenvalues drop sharply after, PC1, while none of the negative eigenvalues seem noteworthy. However, in spatial transcriptomics datasets with single cell resolution, there can be very negative eigenvalues and the corresponding PC is biologically relevant, see this vignette on mouse liver data.
What do these components mean? Each component is a linear combination of genes to maximize the product of variance explained and Moran’s I. The second component maximizes this product provided that it’s orthogonal to the first component, and so on. As the loss in variance explained is usually not huge, these components can be considered axes along which spatially coherent groups of spots are separated from each other as much as possible according to expression of the highly variable genes, so in theory, clustering with positive MULTISPATI components should give more spatially coherent clusters. Because of the spatial coherence, MULTISPATI might be more robust to outliers.
plotDimLoadings(sfe_tissue, dims = 1:4, reduction = "multispati",
swap_rownames = "symbol")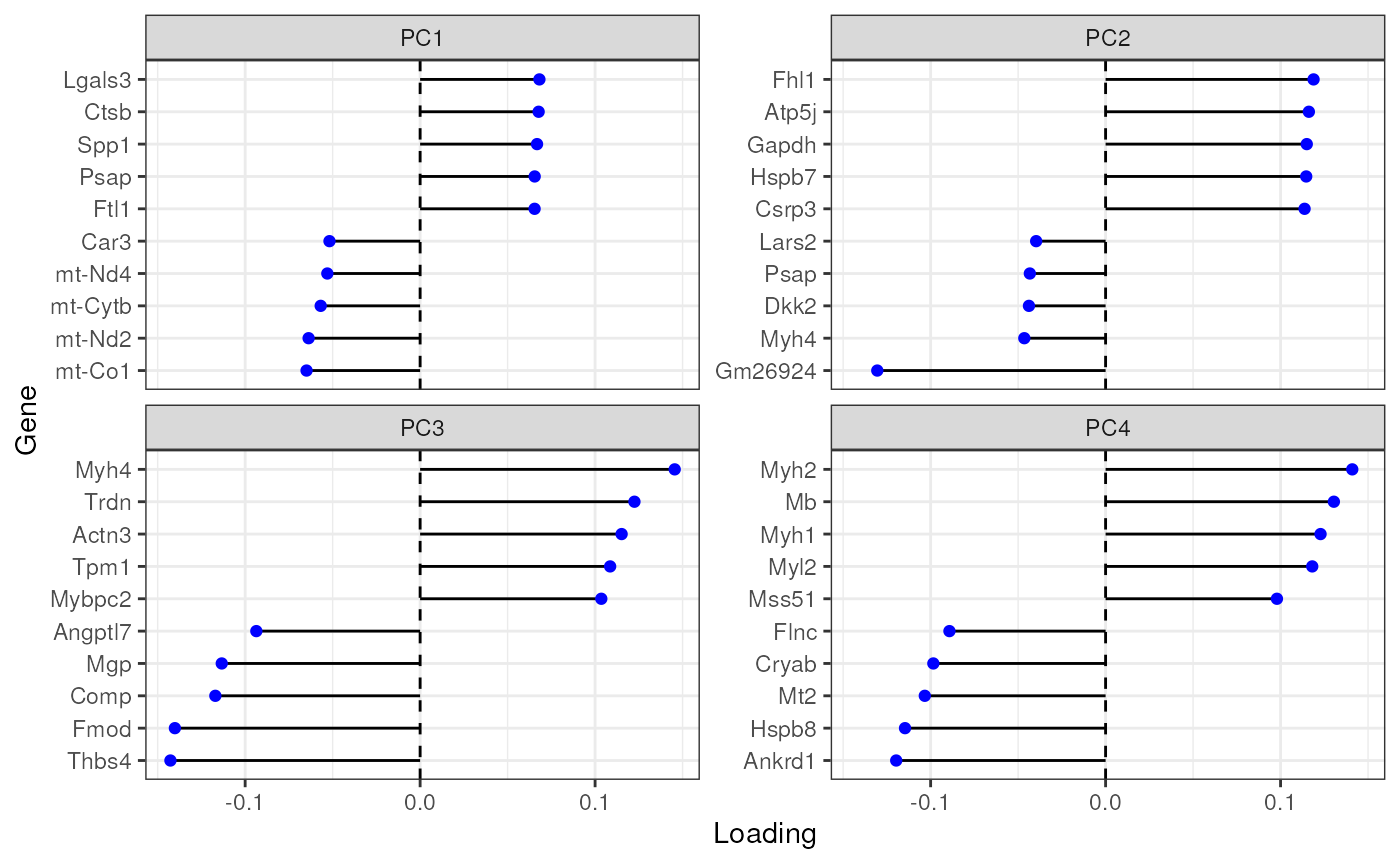
Plot the these PCs:
spatialReducedDim(sfe_tissue, "multispati", 4, divergent = TRUE,
diverge_center = 0, image_id = "lowres")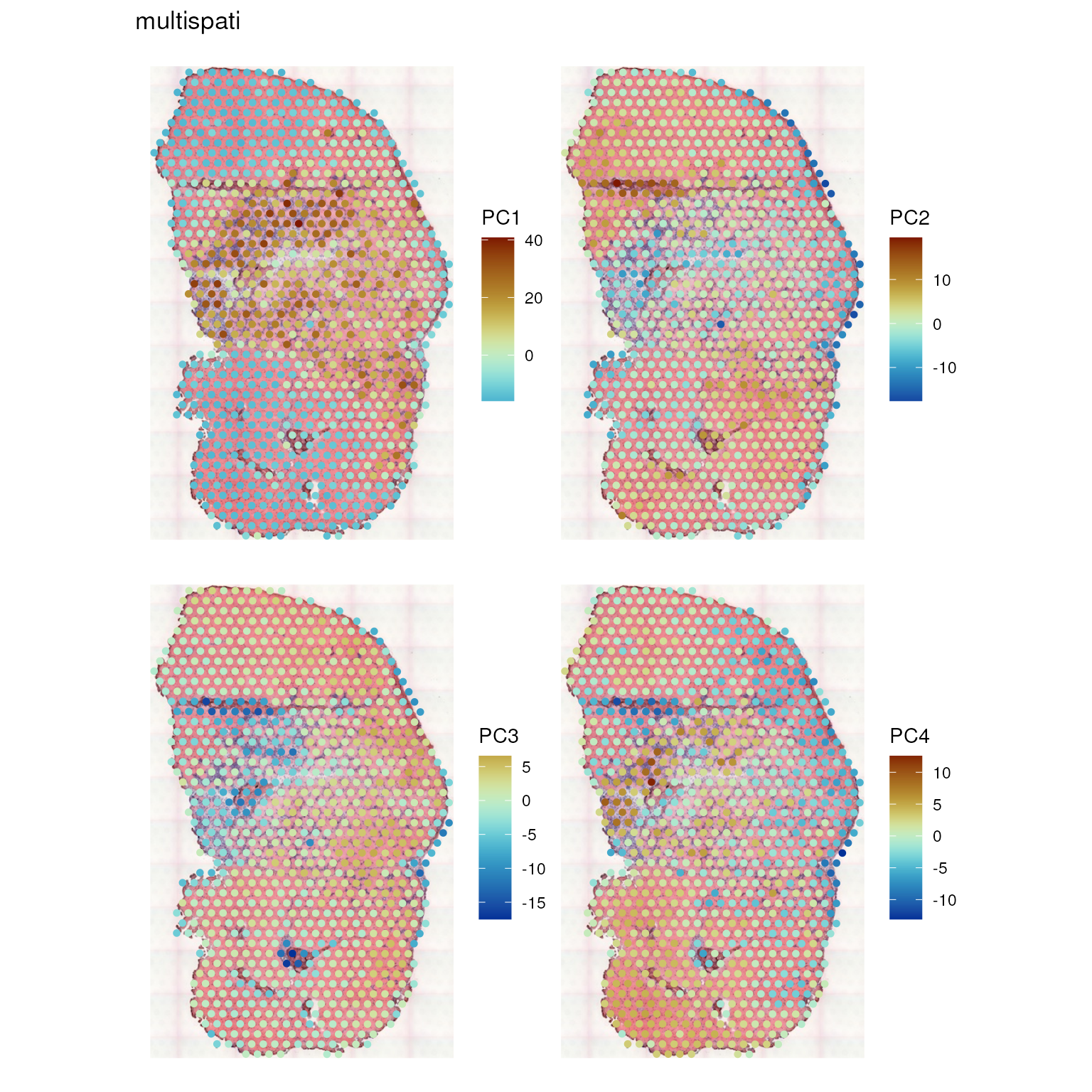
Here unlike in non-spatial PCA, PC4 continues to be spatially structured.
Clustering
PCA embeddings are often used for clustering in scRNA-seq data analysis. Here we perform Leiden clustering on non-spatial and MULTISPATI PCA embeddings.
set.seed(29)
sfe_tissue$clusts_nonspatial <- clusterCells(sfe_tissue, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(
cluster.fun = "leiden",
cluster.args = list(
objective_function = "modularity",
resolution_parameter = 1
)
))See if clustering with the positive MULTISPATI PCs give more spatially coherent clusters
set.seed(29)
sfe_tissue$clusts_multispati <- clusterRows(reducedDim(sfe_tissue, "multispati")[,1:20],
BLUSPARAM = NNGraphParam(
cluster.fun = "leiden",
cluster.args = list(
objective_function = "modularity",
resolution_parameter = 1
)
))Plot the clusters in space:
plotSpatialFeature(sfe_tissue, c("clusts_nonspatial", "clusts_multispati"),
colGeometryName = "spotPoly") &
guides(colour = guide_legend(override.aes = list(size=2), ncol = 2))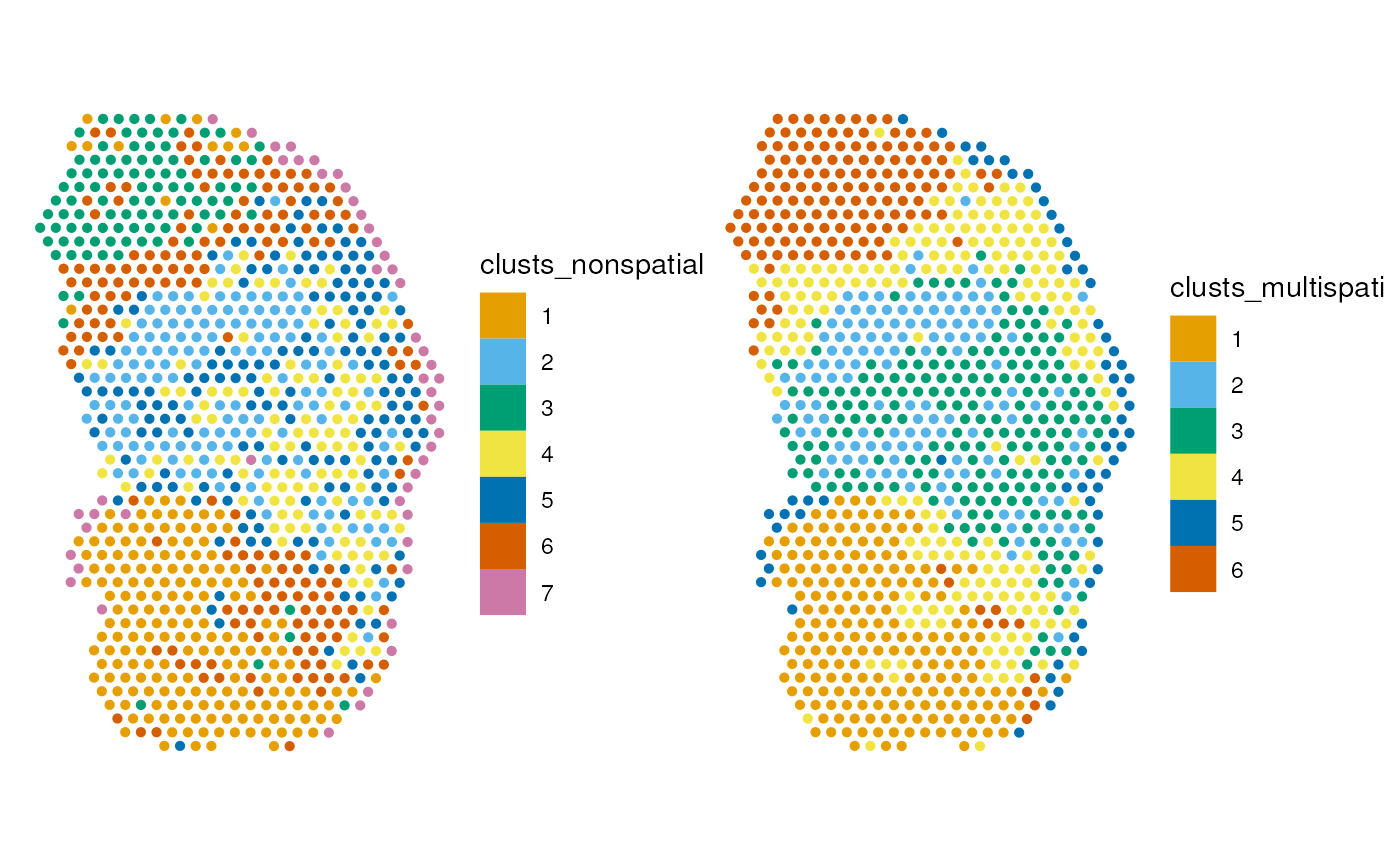
Spatial autocorrelation of principal components
Here we compare Moran’s I for cell embeddings in each non-spatial and
MULTISPATI PC. Just like there’s colDataUnivariate() or
colDataMoransI() for colData columns and
annotGeometryUnivariate() for attributes of annotation
geometries, univariate spatial statistics can be computed for cell/spot
embeddings in reduced dimensions, with
reducedDimUnivariate(), or for Moran’s I,
reducedDimMoransI(). The arguments of all these functions
are similar.
# non-spatial
sfe_tissue <- reducedDimMoransI(sfe_tissue, dimred = "PCA", components = 1:20)
# spatial
sfe_tissue <- reducedDimMoransI(sfe_tissue, dimred = "multispati", components = 1:40)
df_moran <- tibble(PCA = reducedDimFeatureData(sfe_tissue, "PCA")$moran_Vis5A[1:20],
MULTISPATI_pos =
reducedDimFeatureData(sfe_tissue, "multispati")$moran_Vis5A[1:20],
MULTISPATI_neg =
reducedDimFeatureData(sfe_tissue,"multispati")$moran_Vis5A[21:40] |>
rev(),
index = 1:20)
data("ditto_colors")These are the lower and upper bounds of Moran’s I given this spatial neighborhood graph according to (Jong, Sprenger, and Veen 1984).
# Takes a while if not using optimized BLAS
(mb <- moranBounds(colGraph(sfe_tissue, "visium")))
#> Imin Imax
#> -0.5762132 1.0021884
df_moran |>
pivot_longer(cols = -index, values_to = "value", names_to = "name") |>
ggplot(aes(index, value, color = name)) +
geom_line() +
scale_color_manual(values = ditto_colors) +
geom_hline(yintercept = 0, color = "gray") +
geom_hline(yintercept = mb, linetype = 2, color = "gray") +
scale_y_continuous(breaks = scales::breaks_pretty()) +
scale_x_continuous(breaks = scales::breaks_width(5)) +
labs(y = "Moran's I", color = "Type", x = "Component")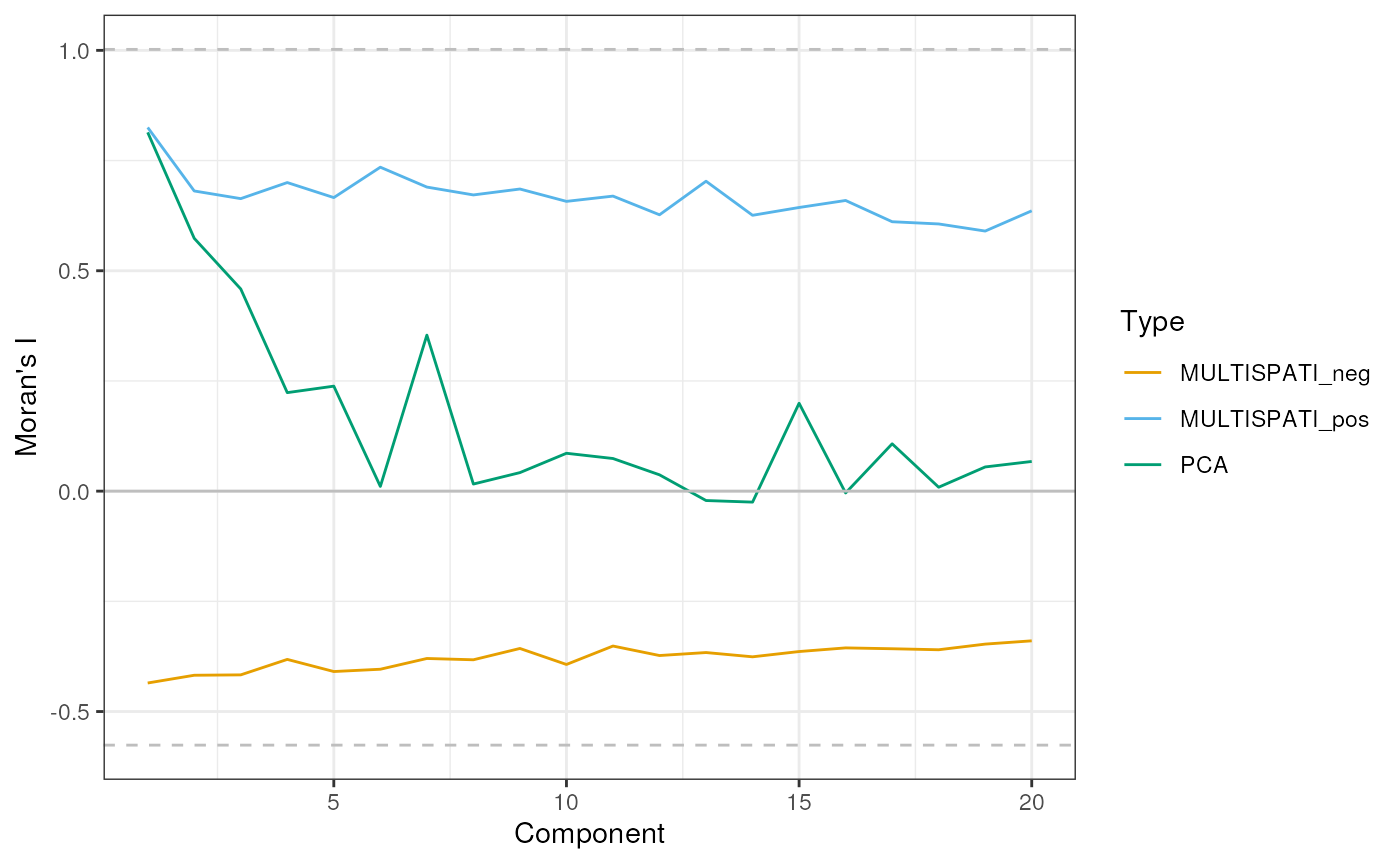
The lower and upper bounds of Moran’s I are plotted as horizontal dashed line. In non-spatial PCA, Moran’s I drops from PC1 to PC6, while Moran’s I remains high for the subsequent MULTISPATI PCs. Given the lower bound of Moran’s I, the negative PCs have strong negative spatial autocorrelation. However, this should not be over-interpreted for this dataset because of the minuscule magnitude of the negative eigenvalues, which means that these PCs explain very little variance.
Exercises
Thought experiment: suppose you perform standard PCA and MULTISPATI PCA on your city, such as on buildings, demographics, or when the city is divided into pixels, on whichever spatial features you find relevant to your life. What would the principal components look like? How would MULTISPATI PC’s differ from the standard PC’s?
Further reading
- The other multivariate spatial method in Voyager as of Bioc 3.17 is a multivariate generalization of local Geary’s C (Anselin 2019). See this vignette on its application to this dataset.
- Unlike similar EDA packages for spatial -omics data, Voyager is extensible, so you can make the uniform user interface run other spatial methods, just like in Tidymodels. See this vignette on extending Voyager.
- There are spatially informed dimension reduction methods designed for spatial -omics data, although they tend to only consider positive spatial autocorrelation. For example, see (Shang and Zhou 2022) and (Velten et al. 2022).
- This paper discusses many other types of multivariate spatial analyses in ecology, besides MULTISPATI PCA (S. Dray et al. 2012).
- MULTISPATI PCA can be thought of as in between two extremes. One
extreme is standard PCA, which diagonalizes the covariance matrix. The
other extreme is the Moran eigen map (MEM) (Griffith 1996), which only uses the spatial
weights matrix, without the data matrix. MEM’s are made by diagonalizing
a double centered spatial weights matrix. The first eigenvector has
values that make the largest possible Moran’s I given the spatial
neighborhood graph. The second eigenvector also maximizes Moran’s I
given that it’s orthogonal to the first eigenvector, and so on. The
eigenvalues are Moran’s I multiplied by a constant. The last eigenvector
has the most negative Moran’s I given the spatial neighborhood graph.
These eigenvectors, or MEM’s, represent spatial structures of different
length scales, which can be selected and used as covariates in
regression to account for spatial autocorrelation, in a procedure called
spatial filtering (Griffith 2000; Griffith and
Peres-Neto 2006). See this
vignette of
adespatialfor examples in ecology.
Caveats
- The H&E image plotted behind the geometries can alter perception of the colors of the geometries.
- Only 2D data is supported at present, although in principle,
sfandGEOSsupport 3D data. - This workshop demonstrates ESDA on a single sample. However, studies often produce multiple biological replica in case and control groups. The ESDA results can be compared across samples, and in the next Bioc 3.18, computed jointly across samples within the same treatment group.
Session info
sessionInfo()
#> R version 4.3.1 (2023-06-16)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: Ubuntu 22.04.2 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: Etc/UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats4 stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] bluster_1.11.3 BiocSingular_1.17.1
#> [3] BiocNeighbors_1.19.0 pheatmap_1.0.12
#> [5] scico_1.4.0 tidyr_1.3.0
#> [7] tibble_3.2.1 BiocParallel_1.35.3
#> [9] patchwork_1.1.2 scales_1.2.1
#> [11] sf_1.0-14 Matrix_1.6-0
#> [13] rjson_0.2.21 scater_1.29.0
#> [15] ggplot2_3.4.2 scran_1.29.0
#> [17] scuttle_1.11.0 SFEData_1.3.0
#> [19] Voyager_1.3.0 SingleCellExperiment_1.23.0
#> [21] SummarizedExperiment_1.31.1 Biobase_2.61.0
#> [23] GenomicRanges_1.53.1 GenomeInfoDb_1.37.2
#> [25] IRanges_2.35.2 S4Vectors_0.39.1
#> [27] BiocGenerics_0.47.0 MatrixGenerics_1.13.1
#> [29] matrixStats_1.0.0 SpatialFeatureExperiment_1.3.0
#> [31] BiocStyle_2.29.1
#>
#> loaded via a namespace (and not attached):
#> [1] later_1.3.1 bitops_1.0-7
#> [3] filelock_1.0.2 R.oo_1.25.0
#> [5] lifecycle_1.0.3 edgeR_3.43.7
#> [7] rprojroot_2.0.3 lattice_0.21-8
#> [9] magrittr_2.0.3 limma_3.57.6
#> [11] sass_0.4.7 rmarkdown_2.23
#> [13] jquerylib_0.1.4 yaml_2.3.7
#> [15] metapod_1.9.0 httpuv_1.6.11
#> [17] sp_2.0-0 RColorBrewer_1.1-3
#> [19] DBI_1.1.3 abind_1.4-5
#> [21] zlibbioc_1.47.0 purrr_1.0.1
#> [23] R.utils_2.12.2 RCurl_1.98-1.12
#> [25] rappdirs_0.3.3 GenomeInfoDbData_1.2.10
#> [27] ggrepel_0.9.3 irlba_2.3.5.1
#> [29] terra_1.7-39 units_0.8-2
#> [31] RSpectra_0.16-1 dqrng_0.3.0
#> [33] pkgdown_2.0.7 DelayedMatrixStats_1.23.0
#> [35] codetools_0.2-19 DropletUtils_1.21.0
#> [37] DelayedArray_0.27.10 tidyselect_1.2.0
#> [39] farver_2.1.1 viridis_0.6.4
#> [41] ScaledMatrix_1.9.1 BiocFileCache_2.9.1
#> [43] jsonlite_1.8.7 e1071_1.7-13
#> [45] ellipsis_0.3.2 systemfonts_1.0.4
#> [47] tools_4.3.1 ggnewscale_0.4.9
#> [49] ragg_1.2.5 Rcpp_1.0.11
#> [51] glue_1.6.2 gridExtra_2.3
#> [53] SparseArray_1.1.11 xfun_0.39
#> [55] dplyr_1.1.2 HDF5Array_1.29.3
#> [57] withr_2.5.0 BiocManager_1.30.21.1
#> [59] fastmap_1.1.1 boot_1.3-28.1
#> [61] rhdf5filters_1.13.5 fansi_1.0.4
#> [63] spData_2.3.0 digest_0.6.33
#> [65] rsvd_1.0.5 R6_2.5.1
#> [67] mime_0.12 textshaping_0.3.6
#> [69] colorspace_2.1-0 wk_0.7.3
#> [71] RSQLite_2.3.1 R.methodsS3_1.8.2
#> [73] utf8_1.2.3 generics_0.1.3
#> [75] class_7.3-22 httr_1.4.6
#> [77] S4Arrays_1.1.5 spdep_1.2-8
#> [79] pkgconfig_2.0.3 gtable_0.3.3
#> [81] blob_1.2.4 XVector_0.41.1
#> [83] htmltools_0.5.5 bookdown_0.34
#> [85] png_0.1-8 SpatialExperiment_1.11.0
#> [87] knitr_1.43 curl_5.0.1
#> [89] proxy_0.4-27 cachem_1.0.8
#> [91] rhdf5_2.45.1 stringr_1.5.0
#> [93] BiocVersion_3.18.0 KernSmooth_2.23-22
#> [95] parallel_4.3.1 vipor_0.4.5
#> [97] AnnotationDbi_1.63.2 desc_1.4.2
#> [99] s2_1.1.4 pillar_1.9.0
#> [101] grid_4.3.1 vctrs_0.6.3
#> [103] promises_1.2.0.1 dbplyr_2.3.3
#> [105] beachmat_2.17.14 xtable_1.8-4
#> [107] cluster_2.1.4 beeswarm_0.4.0
#> [109] evaluate_0.21 magick_2.7.4
#> [111] cli_3.6.1 locfit_1.5-9.8
#> [113] compiler_4.3.1 rlang_1.1.1
#> [115] crayon_1.5.2 labeling_0.4.2
#> [117] classInt_0.4-9 fs_1.6.3
#> [119] ggbeeswarm_0.7.2 stringi_1.7.12
#> [121] viridisLite_0.4.2 deldir_1.0-9
#> [123] munsell_0.5.0 Biostrings_2.69.2
#> [125] ExperimentHub_2.9.1 sparseMatrixStats_1.13.0
#> [127] bit64_4.0.5 Rhdf5lib_1.23.0
#> [129] KEGGREST_1.41.0 statmod_1.5.0
#> [131] shiny_1.7.4.1 highr_0.10
#> [133] interactiveDisplayBase_1.39.0 AnnotationHub_3.9.1
#> [135] igraph_1.5.0.1 memoise_2.0.1
#> [137] bslib_0.5.0 bit_4.0.5